Tidak semua kejadian crash menghasilkan catatan pesan di console Putty. Untuk itu ditambahkan serial console supaya output dari console dapat direkam di komputer lain. Petunjuk menambahkan serial console didapat di artikel “Ubuntu 18.04: GRUB2 and Linux with serial console“
Teknisnya dilakukan dengan mengedit file /etc/default/grub menjadi sebagai berikut:
# If you change this file, run ‘update-grub’ afterwards to update # /boot/grub/grub.cfg. # For full documentation of the options in this file, see: # info -f grub -n ‘Simple configuration’
# Uncomment to enable BadRAM filtering, modify to suit your needs # This works with Linux (no patch required) and with any kernel that obtains # the memory map information from GRUB (GNU Mach, kernel of FreeBSD …) #GRUB_BADRAM=”0x01234567,0xfefefefe,0x89abcdef,0xefefefef”
# Uncomment to disable graphical terminal (grub-pc only) #GRUB_TERMINAL=console
# The resolution used on graphical terminal # note that you can use only modes which your graphic card supports via VBE # you can see them in real GRUB with the command `vbeinfo’ #GRUB_GFXMODE=640×480
# Uncomment if you don’t want GRUB to pass “root=UUID=xxx” parameter to Linux #GRUB_DISABLE_LINUX_UUID=true
# Uncomment to disable generation of recovery mode menu entries #GRUB_DISABLE_RECOVERY=”true”
# Uncomment to get a beep at grub start #GRUB_INIT_TUNE=”480 440 1″ # GRUB_CMDLINE_LINUX=”console=tty1 console=ttyS0,115200″ GRUB_TERMINAL=”console serial” GRUB_SERIAL_COMMAND=”serial –speed=115200 –unit=0 –word=8 –parity=no –stop=1″
Kemudian dilakukan update konfigurai grub dengan aplikasi grub-mkconfig
grub-mkconfig -o /boot/grub/grub.cfg
Setelah itu dilakukan reboot Output dari serial console diambil dari port COM1, kemudian disambungkan ke USB serial yang terhubung ke sebuah laptop. Di laptop dipakai software Putty sebagai terminal serial. Port COM1 sudah ada di motherboard, namun belum terhubung ke konektor DB9, jadi perlu disambungkan dulu dengan tambahan konektor port serial DB9.
Berikut ini prosedur instalasi CUDA driver untuk Nvidia cards di Ubuntu 20.04
CUDA driver ini akan melakukan instalasi GUI, jadi sebaiknya kita pakai Ubuntu Desktop, atau kalau menggunakan Ubuntu server yang belum ada GUInya, install dulu GUI sederhana untuk Ubuntu, misalnya dari artikel “How to Install a Desktop (GUI) on an Ubuntu Server“
Tahap selanjutnya adalah mengikuti prosedur instalasi di artikel “CUDA Toolkit 11.4 Downloads“. Pada laman tersebut kita masukkan saja platform kita. Prosedur instalasi berbeda-beda untuk masing-masing platform.
Sebagai contoh, berikut ini pilihan platform saya:
Untuk Ubuntu, pada saat tulisan ini dibuat hanya dapat dilakukan instalasi di Ubuntu versi 18.04 dan 20.04
Berikut ini prosedur instalasi yang ditampilkan berdasarkan pilihan di atas:
Prosedur tersebut dapat dilakukan apa adanya tanpa perubahan. Jika kita melakukan instalasi di beberapa server yang berbeda, proses download dengan wget cukup dilakukan sekali saja, untuk instalasi berikutnya file *.deb tersebut cukup dikopi dari file yang sudah didownload sebelumnya
Baru saja menemukan masalah di Ubuntu desktop. Pada komputasi dengan beban ringan tidak ada masalah. Tapi kalau ada pengolahan data yang cukup berat terutama yang multi core, muncul pesan dari kernel dan komputer otomatis restart.
Data berikut ini didapat dari remote console (SSH) dengan Putty. Pesan error tidak ada di /var/log, karena kernel panic tidak menghasilkan catatan log.
Kasus di core 5
kernel:[56582.292384] [Hardware Error]: Uncorrected, software restartable error. kernel:[56582.292389] [Hardware Error]: CPU:5 (19:21:0) MC0_STATUS[-|UE|MiscV|AddrV|-|-|-|-|Poison|-]: 0xbc00080001010135 kernel:[56582.292394] [Hardware Error]: Error Addr: 0x0000000212bab300 kernel:[56582.292397] [Hardware Error]: IPID: 0x001000b000000000 kernel:[56582.292400] [Hardware Error]: Load Store Unit Ext. Error Code: 1, An ECC error or L2 poison was detected on a data cache read by a load. kernel:[56582.292405] [Hardware Error]: cache level: L1, tx: DATA, mem-tx: DRD
Kasus di core 5
kernel:[11836.000115] [Hardware Error]: Uncorrected, software restartable error. kernel:[11836.000329] [Hardware Error]: CPU:5 (19:21:0) MC0_STATUS[-|UE|MiscV|AddrV|-|-|-|-|Poison|-]: 0xbc00080001010135 kernel:[11836.000539] [Hardware Error]: Error Addr: 0x00000002c338b300 kernel:[11836.000753] [Hardware Error]: IPID: 0x001000b000000000 kernel:[11836.000964] [Hardware Error]: Load Store Unit Ext. Error Code: 1, An ECC error or L2 poison was detected on a data cache read by a load. kernel:[11836.001178] [Hardware Error]: cache level: L1, tx: DATA, mem-tx: DRD
Kasus di core 10
kernel:[ 259.124195] [Hardware Error]: Uncorrected, software restartable error. kernel:[ 259.124199] [Hardware Error]: CPU:10 (19:21:0) MC0_STATUS[-|UE|MiscV|AddrV|-|-|-|-|Poison|-]: 0xbc00080001010135 kernel:[ 259.124205] [Hardware Error]: Error Addr: 0x00000007a9b2bea0 kernel:[ 259.124207] [Hardware Error]: IPID: 0x001000b000000000 kernel:[ 259.124212] [Hardware Error]: Load Store Unit Ext. Error Code: 1, An ECC error or L2 poison was detected on a data cache read by a load. kernel:[ 259.124216] [Hardware Error]: cache level: L1, tx: DATA, mem-tx: DRD
Kasus di core 11
kernel:[29125.820062] [Hardware Error]: Uncorrected, software restartable error. kernel:[29125.820259] [Hardware Error]: CPU:11 (19:21:0) MC0_STATUS[-|UE|MiscV|AddrV|-|-|-|-|Poison|-]: 0xbc00080001010135 kernel:[29125.820479] [Hardware Error]: Error Addr: 0x00000007ca1d9880 kernel:[29125.820681] [Hardware Error]: IPID: 0x001000b000000000 kernel:[29125.820892] [Hardware Error]: Load Store Unit Ext. Error Code: 1, An ECC error or L2 poison was detected on a data cache read by a load. kernel:[29125.821100] [Hardware Error]: cache level: L1, tx: DATA, mem-tx: DRD
Ryzen 5600X memiliki 6 core dengan 12 thread. Dari 12 itu, 3 bermasalah.
Pengukuran #2 (via serial console)
Tidak semua kejadian crash menghasilkan catatan pesan di console Putty. Untuk itu ditambahkan serial console supaya output dari console dapat direkam di komputer lain. Petunjuk menambahkan serial console di Ubuntu dirangkum ditulisan “Serial Console di Ubuntu 20.04“
Berikut ini hasil rekaman crash dengan serial console
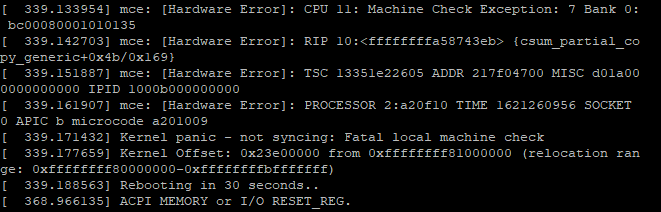
Berikut teks rekaman kernel panic tersebut di detik 339
[25552.847056] mce: [Hardware Error]: CPU 11: Machine Check Exception: 7 Bank 0: bc00080001010135 [25552.856356] mce: [Hardware Error]: RIP 10:<ffffffff9487156e> {copy_user_enhanced_fast_string+0xe/0x30} [25552.865975] mce: [Hardware Error]: TSC 55e329c132c5 ADDR 16fcb7680 MISC d01a000000000000 IPID 1000b000000000 [25552.876436] mce: [Hardware Error]: PROCESSOR 2:a20f10 TIME 1621288267 SOCKET 0 APIC b microcode a201009 [25552.886316] Kernel panic – not syncing: Fatal local machine check
Percobaan di Windows
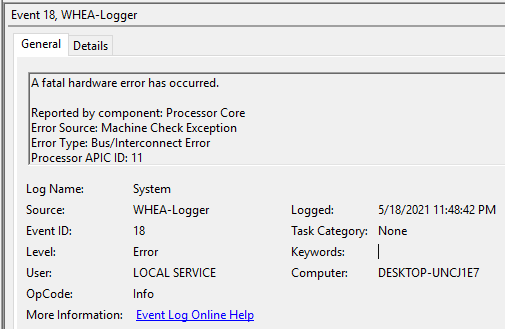
Percobaan berikut ini dilakukan di Windows 10. Dilakukan pengujian beban komputasi yang banyak. Setelah beberapa jam, komputer restart sendiri. Pesan kesalahan dilihat di Event Viewer. Pesan error berikut ini menandakan ada masalah di core 11:
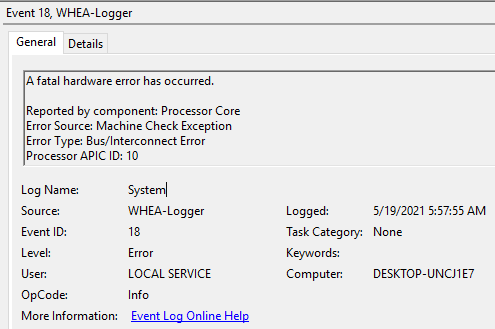
Percobaan diulangi lagi. Setelah beberapa jam, muncul pesan kesalahan. Pada kesempatan ini yang error adalah core 10:
Analisis
Dari hasil membaca berbagai artikel, kemungkinan ada cacat fisik di core nomor 5,10 dan 11 Referensi:
Readability Assessment for Text Simplification – We describe a readability assessment approach to support the process of text simplification for poor literacy readers. Given an input text, the goal is to predict its readability level, which corresponds to the literacy level that is expected from the target reader: rudimentary, basic or advanced.
Integrating LSA-based hierarchical conceptual space and machine learning methods for leveling the readability of domain-specific texts – Text readability assessment is a challenging interdisciplinary endeavor with rich practical implications. It has long drawn the attention of researchers internationally, and the readability models since developed
have been widely applied to various fields. Previous readability models have only made use of linguistic features employed for general text analysis and have not been sufficiently accurate when used to gauge domain-specific texts.
Deep Learning for Prominence Detection in Children’s Read Speech – A previous well-tuned random forest ensemble predictor is replaced by an RNN sequence classifier to exploit potential context dependency across the longer utterance. Further, deep learning is applied to obtain word-level features from low-level acoustic contours of fundamental frequency, intensity and spectral shape in an end-to-end fashion. Performance comparisons are presented across the different feature types and across different feature learning architectures for prominent word prediction to draw insights wherever possible.
Zhigang Dai, Bolun Cai, Yugeng Lin, Junying Chen, UP-DETR: Unsupervised Pre-training for Object Detection with Transformers – The model is pre-trained to detect these query patches from the original image. During the pre-training, we address two critical issues: multi-task learning and multi-query localization. (1) To trade-off multi-task learning of classification and localization in the pretext task, we freeze the CNN backbone and propose a patch feature reconstruction branch which is jointly optimized with patch detection. (2) To perform multi-query localization, we introduce UP-DETR from single-query patch and extend it to multi-query patches with object query shuffle and attention mask.
Strawberry Detection Using a Heterogeneous Multi-Processor Platform. This paper proposes using the You Only Look Once version 3 (YOLOv3) Convolutional Neural Network (CNN) in combination with utilising image processing techniques for the application of precision farming robots targeting strawberry detection, accelerated on a heterogeneous multiprocessor platform. The results show a performance acceleration by five times when implemented on a Field-Programmable Gate Array (FPGA) when compared with the same algorithm running on the processor side with an accuracy of 78.3\% over the test set comprised of 146 images.
Bag of Freebies for Training Object Detection Neural Networks [paperswithcode] In this works, we explore training tweaks that apply to various models including Faster R-CNN and YOLOv3. These tweaks do not change the model architectures, therefore, the inference costs remain the same. Our empirical results demonstrate that, however, these freebies can improve up to 5% absolute precision compared to state-of-the-art baselines.
Berikut ini perbandingan parameter-parameter penting SSD NVMe dengan kapasitas 1 TB, dengan interface M.2.
SSD WD Blue SN550 NVMe
Tipe-tipe yang dipilih pada tabel berikut ini adalah yang tersedia di pasaran pada bulan April 2021.
Data terutama diperoleh dari situs resmi pabrikan masing-masing SSD. Beberapa produk tidak menyertakan TBW (Terabytes Written) di situsnya, sehingga data TBW perlu dicari dari situs review terkait.