This tutorial shows how to do multiclass image classification with Keras, using keras.preprocessing.image.flow_from_directory() to feed the image files for training and prediction.
 |
||
| Plant Seedlings Classification dataset |
Prepare Directory Structure
- download dataset from https://www.kaggle.com/c/plant-seedlings-classification/data
- put original training files in <root>/data/train
- put original test files in <root>/data/test/0 . Caution: test files must be put into a directory under /data/test. For simplicity, we create /data/test/0, but any directory name is okay, as long as it is under /data/test
- create <root>/plant-src to store source codes
Here is the directory structure after previous steps:

Import Libraries
import tensorflow as tf
import keras as keras
import os
from keras.layers import Flatten, Dense, AveragePooling2D, GlobalAveragePooling2D
from keras.models import Model
from keras.optimizers import RMSprop, SGD
from keras.callbacks import ModelCheckpoint
from keras.callbacks import EarlyStopping
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import CSVLogger
from keras.layers.normalization import BatchNormalization
import numpy as np
from keras.models import load_model
from pathlib import Path
import shutil
Make Training & Validation Directories
Create directories for training and validation set. A little bit complicated, since flow_from_directory() required that each class has it’s own directory.
#making training & validation directories
import pathlib
session='simpleNASNet'
classnames=['Black-grass','Charlock','Cleavers','Common Chickweed','Common wheat','Fat Hen','Loose Silky-bent','Maize','Scentless Mayweed','Shepherds Purse','Small-flowered Cranesbill','Sugar beet']
train_dir="../"+session+"/train"
valid_dir="../"+session+"/valid"
for dirname in classnames:
# print(dirname)
fulldirname=train_dir+'/'+dirname
print(fulldirname)
pathlib.Path(fulldirname).mkdir(parents=True, exist_ok=True)
fulldirname=valid_dir+'/'+dirname
print(fulldirname)
pathlib.Path(fulldirname).mkdir(parents=True, exist_ok=True)
Split training data between training set and validation set. Usual 80%-20% split is used.
#copy image files, split 80% training- 20% validation
counter=0
for root, dirs, files in os.walk(original_data_dir):
for file in files:
fullfilename = os.path.join(root, file)
basename=os.path.basename(fullfilename)
#detect image classification from directory name
split1=os.path.split(fullfilename)
split2=os.path.split(split1[0])
classname=str(split2[1])#classname for this particular file
if((counter%5)==0): #copy validation
dst_filename=valid_dir+"/"+classname+"/"+basename
shutil.copyfile(fullfilename,dst_filename)
else: #copy training
dst_filename=train_dir+"/"+classname+"/"+basename
shutil.copyfile(fullfilename,dst_filename)
counter=counter+1
Model
Prepare model, we use NASNet with 331×331 input, using pre-trained weight from Imagenet. Top layers are omitted, and replaced with a Dense layer of 1024 cells and 12 cells output layer for each class. Output activation is softmax, which is usual for multiclass classification.
#prepare model
img_width=331
img_height=331
network_notop = keras.applications.nasnet.NASNetLarge(input_shape=(img_width, img_height, 3),
include_top=False,
weights='imagenet', input_tensor=None,
pooling=None)
x = network_notop.output
x = GlobalAveragePooling2D()(x)
x = Dense(1024, activation='relu')(x)
x = BatchNormalization()(x)
predictions = Dense(12, activation='softmax')(x)
the_model = Model(network_notop.input, predictions)
Training
Standard training.
Specific parameter for multiclass classification:
- loss=’categorical_crossentropy’ in model.compile()
- class_mode=’categorical’ in flow_from_directory()
#training
learning_rate = 0.0001
logfile = session + '-train' + '.log'
batch_size=4
nbr_epochs=10
print("training directory: "+train_dir)
print("valication directory: "+valid_dir)
optimizer = SGD(lr=learning_rate, momentum=0.9, decay=0.0, nesterov=True)
the_model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
csv_logger = CSVLogger(logfile, append=True)
early_stopping = EarlyStopping(monitor='val_loss', min_delta=0, patience=10, verbose=1, mode='auto')
best_model_filename=session+'-weights.{epoch:02d}-{val_loss:.2f}.h5'
best_model = ModelCheckpoint(best_model_filename, monitor='val_acc', verbose=1, save_best_only=True)
# this is the augmentation configuration we will use for training
train_datagen = ImageDataGenerator(
rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
rotation_range=90,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True,
vertical_flip=True)
val_datagen = ImageDataGenerator(rescale=1. / 255)
print('prepare train generator')
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
shuffle=True,
classes=classnames,
class_mode='categorical')
print('prepare validation generator')
validation_generator = val_datagen.flow_from_directory(
valid_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
shuffle=True,
classes=classnames,
class_mode='categorical')
print('fit generator')
the_model.fit_generator(
generator=train_generator,
epochs=nbr_epochs,
verbose=1,
validation_data=validation_generator,
callbacks=[best_model, csv_logger, early_stopping])
Training progress
training directory: ../simpleNASNet/train
valication directory: ../simpleNASNet/valid
prepare train generator
Found 3800 images belonging to 12 classes.
prepare validation generator
Found 950 images belonging to 12 classes.
fit generator
Epoch 1/10
950/950 [==============================] - 635s 669ms/step - loss: 1.2295 - acc: 0.6039 - val_loss: 0.6469 - val_acc: 0.7979
Epoch 00001: val_acc improved from -inf to 0.79789, saving model to simpleNASNet-weights.01-0.65.h5
Epoch 2/10
950/950 [==============================] - 557s 586ms/step - loss: 0.6281 - acc: 0.7929 - val_loss: 0.3840 - val_acc: 0.8674
Epoch 00002: val_acc improved from 0.79789 to 0.86737, saving model to simpleNASNet-weights.02-0.38.h5
Epoch 3/10
950/950 [==============================] - 557s 586ms/step - loss: 0.5220 - acc: 0.8345 - val_loss: 0.3026 - val_acc: 0.9000
Epoch 00003: val_acc improved from 0.86737 to 0.90000, saving model to simpleNASNet-weights.03-0.30.h5
Epoch 4/10
950/950 [==============================] - 558s 587ms/step - loss: 0.4369 - acc: 0.8566 - val_loss: 0.2830 - val_acc: 0.9105
Epoch 00004: val_acc improved from 0.90000 to 0.91053, saving model to simpleNASNet-weights.04-0.28.h5
Epoch 5/10
950/950 [==============================] - 558s 588ms/step - loss: 0.3722 - acc: 0.8842 - val_loss: 0.2310 - val_acc: 0.9253
Epoch 00005: val_acc improved from 0.91053 to 0.92526, saving model to simpleNASNet-weights.05-0.23.h5
Epoch 6/10
950/950 [==============================] - 559s 588ms/step - loss: 0.3213 - acc: 0.8966 - val_loss: 0.2210 - val_acc: 0.9232
Epoch 00006: val_acc did not improve from 0.92526
Epoch 7/10
950/950 [==============================] - 556s 585ms/step - loss: 0.3202 - acc: 0.8939 - val_loss: 0.2190 - val_acc: 0.9263
Epoch 00007: val_acc improved from 0.92526 to 0.92632, saving model to simpleNASNet-weights.07-0.22.h5
Epoch 8/10
950/950 [==============================] - 559s 589ms/step - loss: 0.2997 - acc: 0.9063 - val_loss: 0.1861 - val_acc: 0.9389
Epoch 00008: val_acc improved from 0.92632 to 0.93895, saving model to simpleNASNet-weights.08-0.19.h5
Epoch 9/10
950/950 [==============================] - 554s 584ms/step - loss: 0.2469 - acc: 0.9203 - val_loss: 0.1942 - val_acc: 0.9379
Epoch 00009: val_acc did not improve from 0.93895
Epoch 10/10
950/950 [==============================] - 557s 587ms/step - loss: 0.2619 - acc: 0.9147 - val_loss: 0.1695 - val_acc: 0.9421
Epoch 00010: val_acc improved from 0.93895 to 0.94211, saving model to simpleNASNet-weights.10-0.17.h5
Prediction & Submission
Caution: test files must be put into a directory under /data/test. For simplicity, we create /data/test/0, but any directory name is okay, as long as it is under /data/test . This behavior is quite strange, but maybe to make flow_from_directory() work the same way for training phase and prediction/inference phase.
#prediction
batch_size=4
nbr_test_samples=794
img_width=331
img_height=331
#choose weights file manually
weights_path = 'simpleNASNet-weights.10-0.17.h5' # choose file manually, filename may be different
test_data_dir = '../data/test/'
test_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_directory(
test_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
shuffle = False, # no shuffling, since filenames must match predictions. Shuffling may change file sequence
classes = None, #
class_mode = None)
test_image_list = test_generator.filenames
print('Loading model and weights')
predict_model = load_model(weights_path)
print('Begin to predict for testing data ...')
predictions = predict_model.predict_generator(test_generator, nbr_test_samples)
np.savetxt(session+'-predictions.txt', predictions) # store prediction matrix, for later analysis if necessary
Constructing submission file
#submission
submission_file=session+'-submit.csv'
print('Begin to write submission file:'+submission_file)
f_submit = open(submission_file, 'w')
f_submit.write('file,speciesn')
for i, image_name in enumerate(test_image_list):
# find maximum prediction of 12
max_index=0
max_value=0
for x in range(0, 12):
if(predictions[i][x]>max_value):
max_value=predictions[i][x]
max_index=x
basename=os.path.basename(image_name)
prediction_class = classnames[max_index] # get predictions from array
f_submit.write('%s,%sn' % (basename, prediction_class))
f_submit.close()
print('Finished write submission file ..')
To check final score, let’s go to Late Submission page in Kaggle Plant Seedlings Classification. The score is 0.96095, which ranks about 400 in leaderboard.
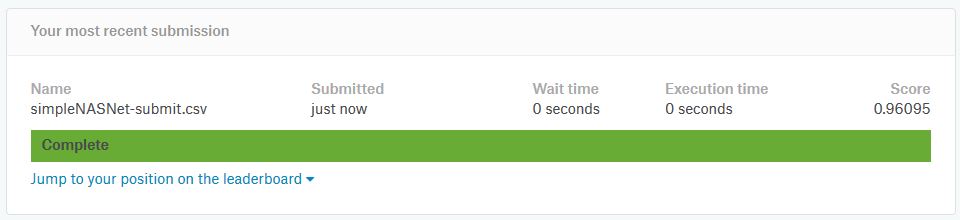 |
| Late submission score |