Buku tentang prinsip-prinsip dan teknik merekayasa sistem berbasis kecerdasan tiruan (AI).

Sumber: https://mlsysbook.ai/
Buku tentang prinsip-prinsip dan teknik merekayasa sistem berbasis kecerdasan tiruan (AI).
Sumber: https://mlsysbook.ai/
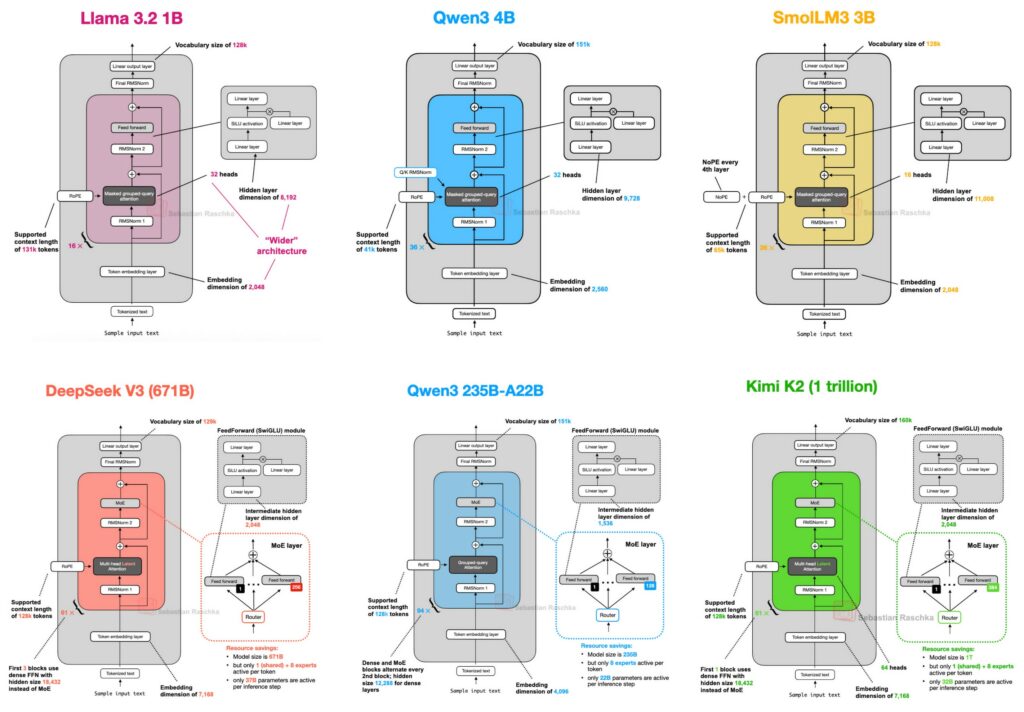
Perbandingan beberapa arsitektur LLM besar. Sumber: https://magazine.sebastianraschka.com/p/the-big-llm-architecture-comparison
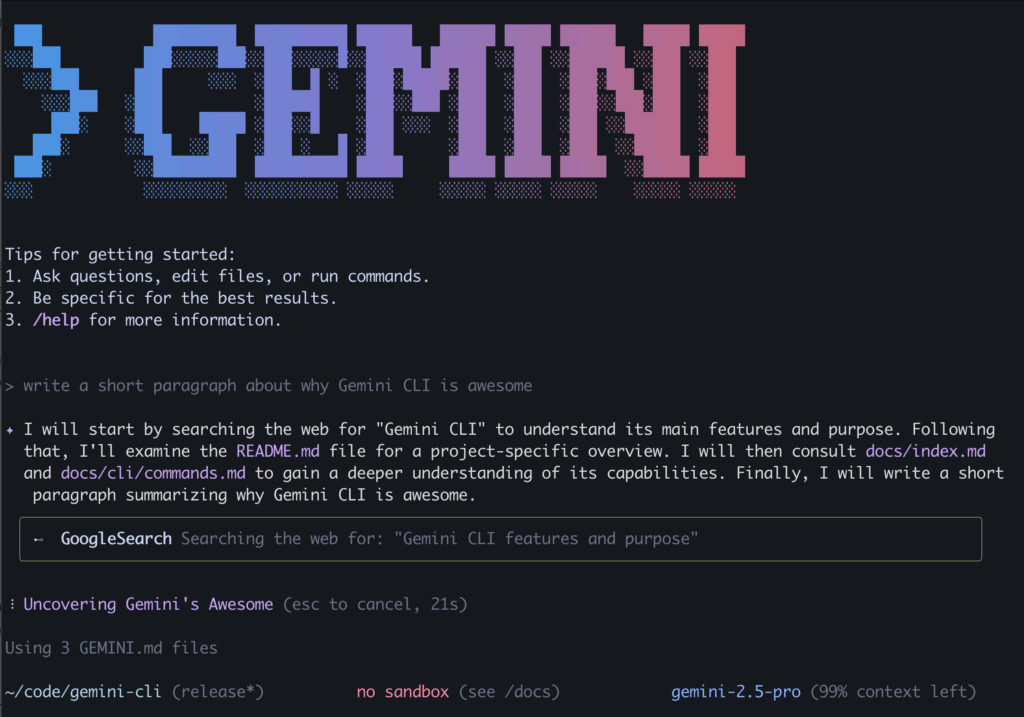
Gemini LLM AI dapat diakses dari command line. Prosedur instalasinya di https://github.com/google-gemini/gemini-cli
Buku Tentang Radar, gratis nih.
Judul buku : “Engineering for Advanced Radar and Electromagnetic Spectrum Operations; New Era of Security”

Beberapa model AI diklaim mampu melakukan proses berpikir secara penalaran (reasoning), misalnya Claude, DeepSeek dan sebagainya. Penelitian oleh Apple menunjukkan sebenarnya model-model tersebut tidak melakukan penalaran.

Referensi: https://x.com/RubenHssd/status/1931389580105925115
Berikut ini beberapa studi tentang efek AI terhadap produktivitas manusia
Penelitian di Denmark menggunakan survey menunjukkan bahwa AI chatbot menaikkan produktivitas 3%
“We examine the labor market effects of AI chatbots using two large-scale adoption surveys (late 2023 and 2024) covering 11 exposed occupations (25,000 workers, 7,000 workplaces), linked to matched employer-employee data in Denmark. AI chatbots are now widespread—most employers encourage their use, many deploy in-house models, and training initiatives are common. These firm-led investments boost adoption, narrow demographic gaps in take-up, enhance workplace utility, and create new job tasks. Yet, despite substantial investments, economic impacts remain minimal. Using difference-in-differences and employer policies as quasi-experimental variation, we estimate precise zeros: AI chatbots have had no significant impact on earnings or recorded hours in any occupation, with confidence intervals ruling out effects larger than 1%. Modest productivity gains (average time savings of 3%), combined with weak wage pass-through, help explain these limited labor market effects. Our findings challenge narratives of imminent labor market transformation due to Generative AI.” https://papers.ssrn.com/sol3/papers.cfm?abstract_id=5219933
Tautan paper: https://shapingwork.mit.edu/research/the-simple-macroeconomics-of-ai/
Artikel: https://mitsloan.mit.edu/ideas-made-to-matter/a-new-look-economics-ai
In a new paper, “The Simple Macroeconomics of AI,” MIT Institute Professor has a more conservative estimate of how AI will affect the U.S. economy over the next 10 years. Estimating that only about 5% of tasks will be able to be profitably performed by AI within that time frame, the GDP boost would likely be closer to 1% over that period, Acemoglu suggests. This is a “nontrivial, but modest effect, and certainly much less than both the revolutionary changes some are predicting and the less hyperbolic but still substantial improvements forecast by Goldman Sachs and the McKinsey Global Institute,” he writes.
Seseorang menemukan kelemahan zeroday di Linux dengan bantuan LLM OpenAI o3. Link: https://sean.heelan.io/2025/05/22/how-i-used-o3-to-find-cve-2025-37899-a-remote-zeroday-vulnerability-in-the-linux-kernels-smb-implementation/
Links
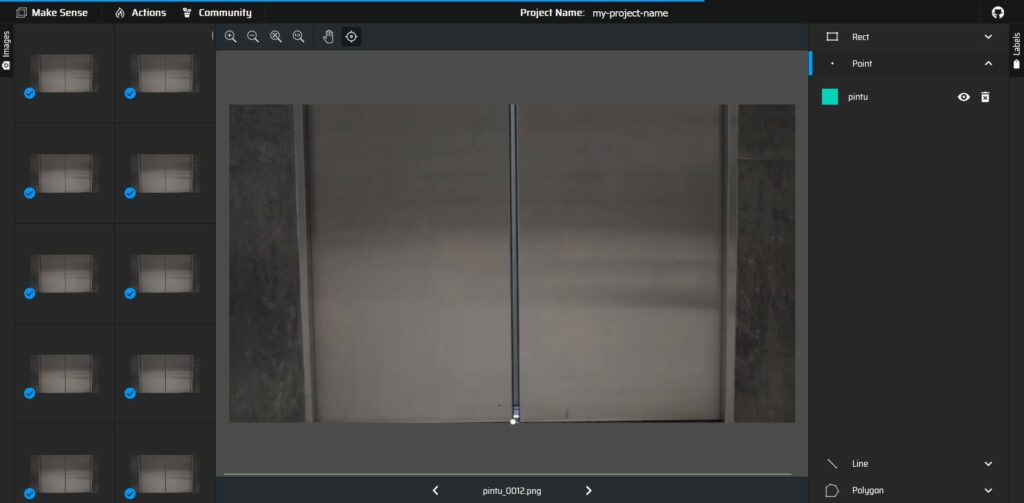
Sumber data: video pergerakan pintu lift : https://www.youtube.com/watch?v=j_KKJnDDxQY
Video diubah menjadi image menggunakan software ffmpeg:
ffmpeg -i pintu-lift.mov pintu_%04d.pngPosisi pintu dianotasi secara manual menggunakan software Make Sense AI (https://www.makesense.ai/). Hasil anotasi diexport menggunakan format CSV.
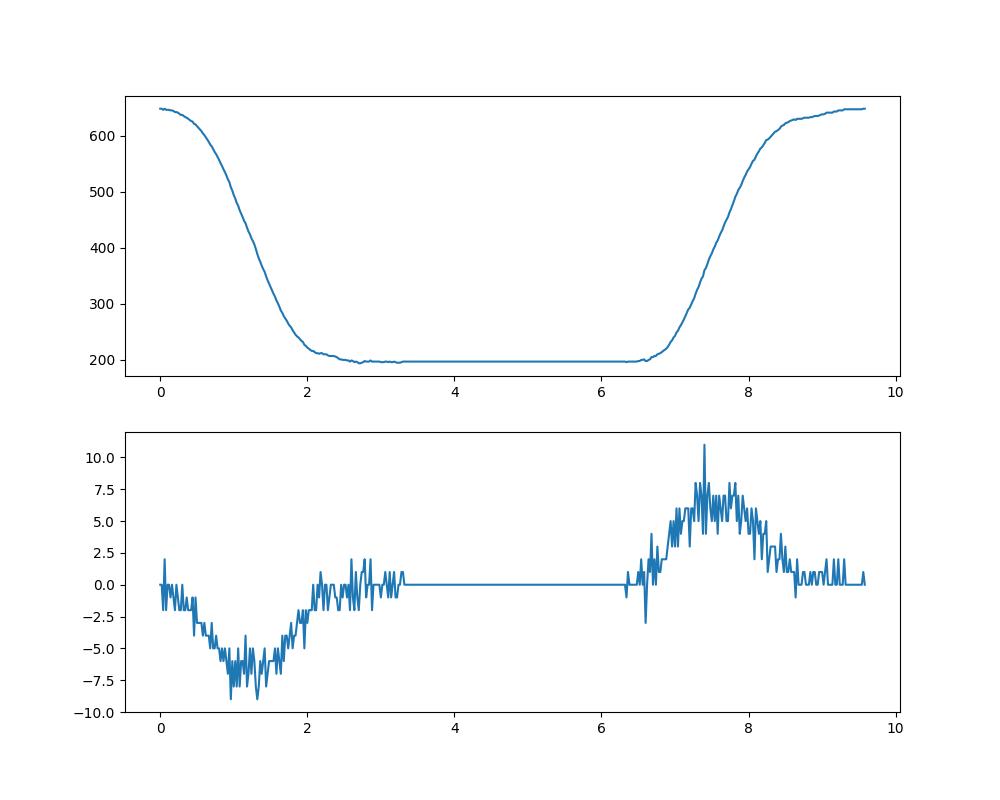
Data dalam bentuk CSV kemudian diolah dengan Python & Jupyter Notebook .
Berikut hasil grafiknya:
AI sebagai alat bantu penulisan karya ilmiah. Sumber artikel: “Artificial intelligence-assisted academic writing: recommendations for ethical use ” Berikut ini abstraknya.
Generative artificial intelligence (AI) tools have been selectively adopted across the academic community to help researchers complete tasks in a more efficient manner. The widespread release of the Chat Generative Pre-trained Transformer (ChatGPT) platform in 2022 has made these tools more accessible to scholars around the world. Despite their tremendous potential, studies have uncovered that large language model (LLM)-based generative AI tools have issues with plagiarism, AI hallucinations, and inaccurate or fabricated references. This raises legitimate concern about the utility, accuracy, and integrity of AI when used to write academic manuscripts. Currently, there is little clear guidance for healthcare simulation scholars outlining the ways that generative AI could be used to legitimately support the production of academic literature. In this paper, we discuss how widely available, LLM-powered generative AI tools (e.g. ChatGPT) can help in the academic writing process. We first explore how academic publishers are positioning the use of generative AI tools and then describe potential issues with using these tools in the academic writing process. Finally, we discuss three categories of specific ways generative AI tools can be used in an ethically sound manner and offer four key principles that can help guide researchers to produce high-quality research outputs with the highest of academic integrity.
100-an mobil dikendalikan dengan algoritma AI berbasis RL untuk meningkatkan efisiensi dan mengurangi kemacetan.
Artikel Populer: Scaling Up Reinforcement Learning for Traffic Smoothing: A 100-AV Highway Deployment
