Standard Scaler: semua fitur (input) memiliki nilai rata-rata 0 dan variansi=1
Robust Scaler: seperti Standard Scaler, namun menggunakan median dan kuartil
MinMax Scaler: semua fitur memiliki nilai minimum 0 dan nilai maksimum 1
Normalizer: semua fitur diperlakukan sebagai vektor, dan panjang euclidian dibuat menjadi 1. Dipakai kalau kita hanya perlu besaran arah/sudut/rasio dari vektor, dan tidak memerlukan nilai mutlaknya.
Kategori: Uncategorized
Internet of Things Untuk Aplikasi Militer

Berikut ini teknologi-teknologi yang dipakai untuk IoT pada militer [PTM2016]
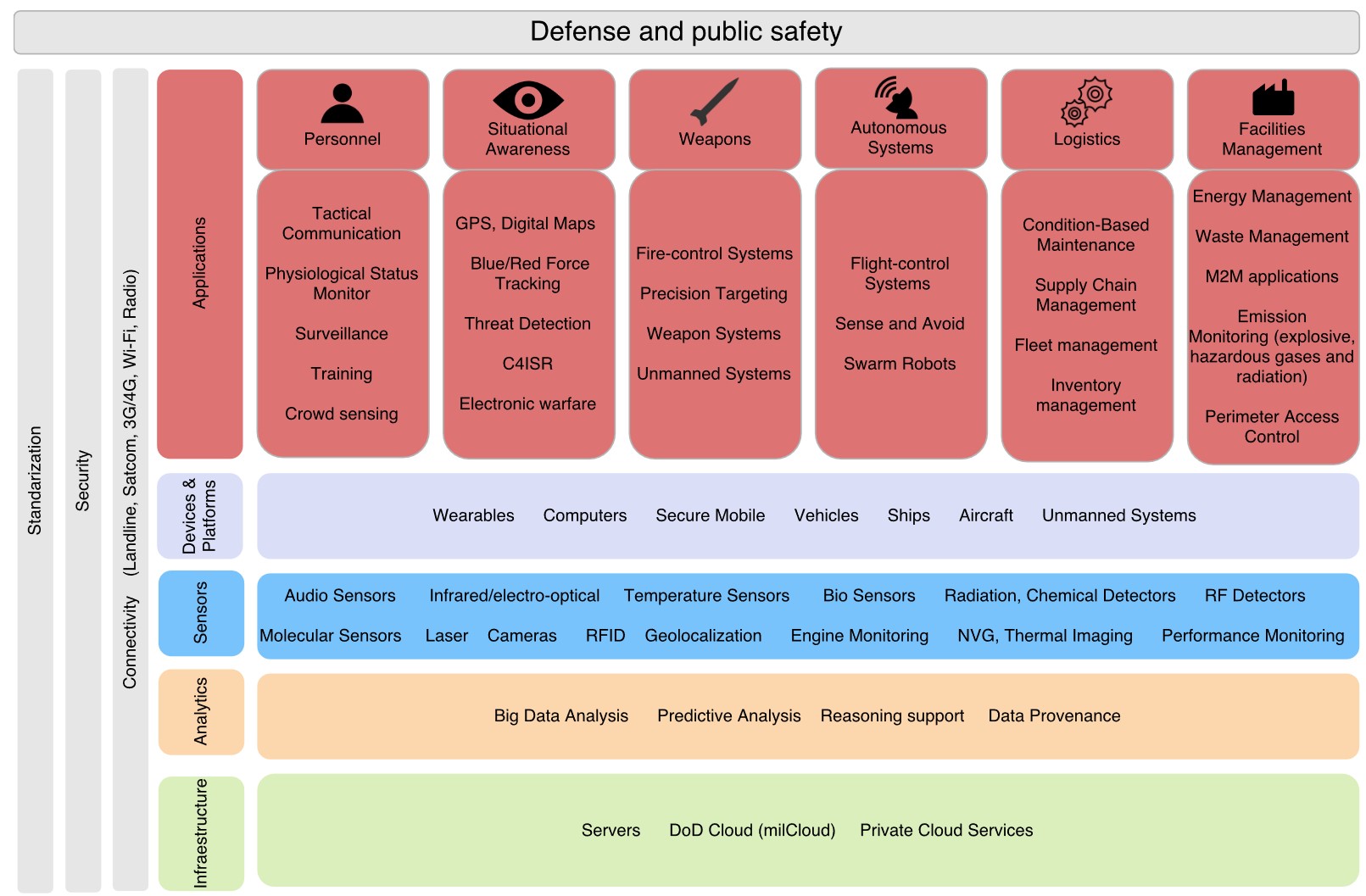
Referensi Texbook
Referensi Jurnal
Referensi Artikel
- Wikipedia: Internet of Military Things
- IoT Security: In today’s world, military-grade all-round?
- Defence Internet of Things (dIoT)
- Defense Policy and the Internet of Things Disrupting Global Cyber Defenses [PDF]
Teknik Pengukuran Trafik ke Suatu Domain
![]()
Pengukuran trafik web ke suatu domain dan semua sub domainnya dapat dilakukan dengan beberapa cara:
- analisis log di semua web server. Paling tepat, cuma lumayan melelahkan kalau dalam suatu lembaga/perusahaan terdapat banyak web server.
- analisis jumlah trafik di port 80 dan 443 dari luar organisasi ke dalam organisasi tersebut. Angka ini bisa didapat dari log router organisasi, namun mesti lognya mesti diaktifkan dulu, dan routernya mendukung. Kalau tidak diaktifkan, rekamannya tidak ada.
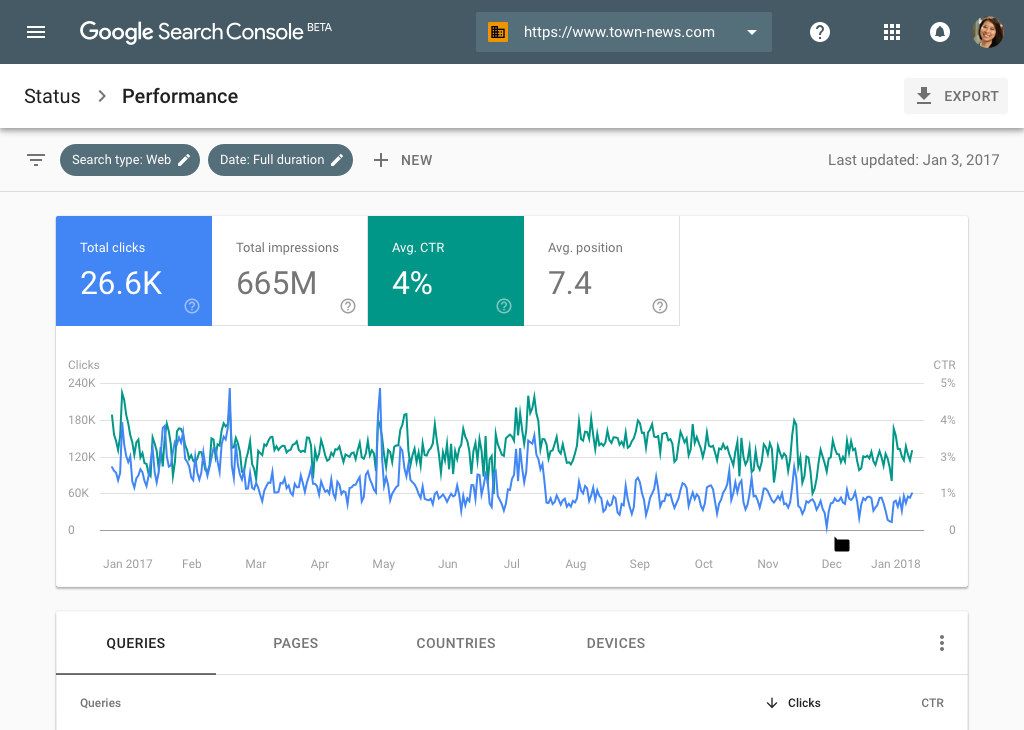
- menggunakan Google Search Console, yaitu rekaman Google Search. Keuntungannya data ini tersedia gratis di Google, dan kita tidak perlu melakukan konfigurasi apapun di server kita. . Kelemahan: hanya mencatat trafik yang berasal dari Google search engine. Trafik dari search engine lain, dari website lain tidak tercatat. Mestinya data trafik Google cukup mewakili, karena biasanya mayoritas trafik web ke suatu organisasi berasal dari hasil search engine Google.
Referensi
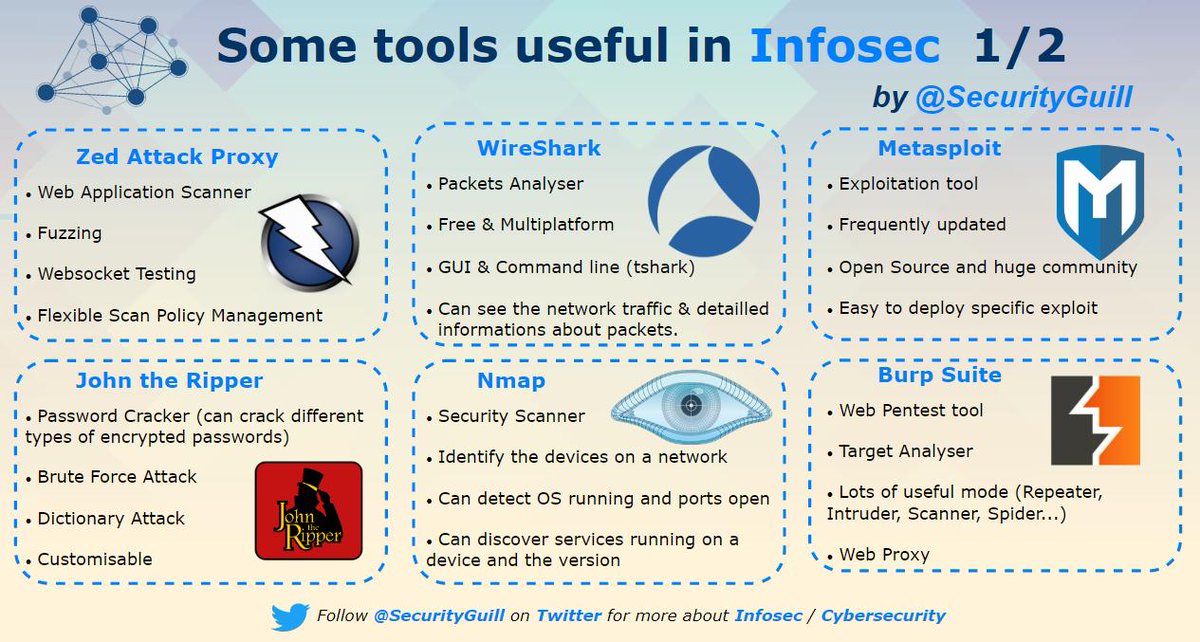
Security Infografik
Sumber:
- https://twitter.com/SecurityGuill
- https://securityguill.com/
- https://twitter.com/SecurityGuill/status/1368241476753371140
How does an Antivirus works?

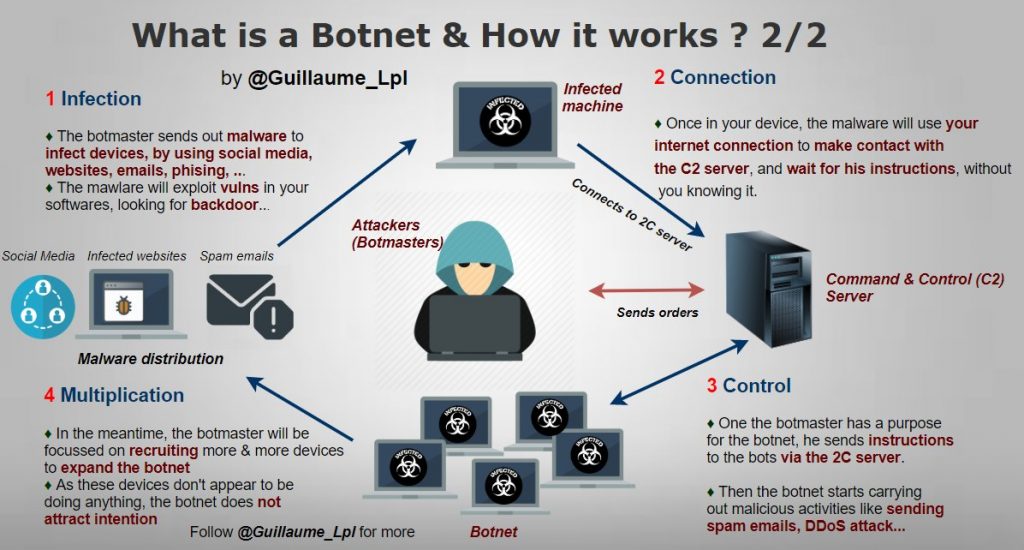
What is a Botnet & How it works

What is a Bug Bounty?

What is a DDos Attack?


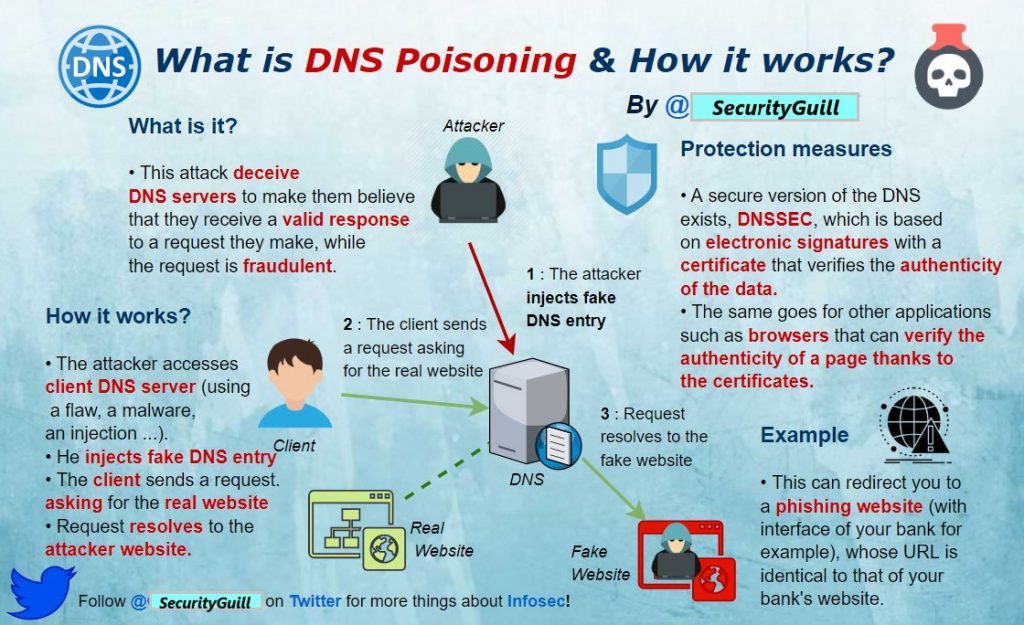
What is DNS Poisoning & How it works?
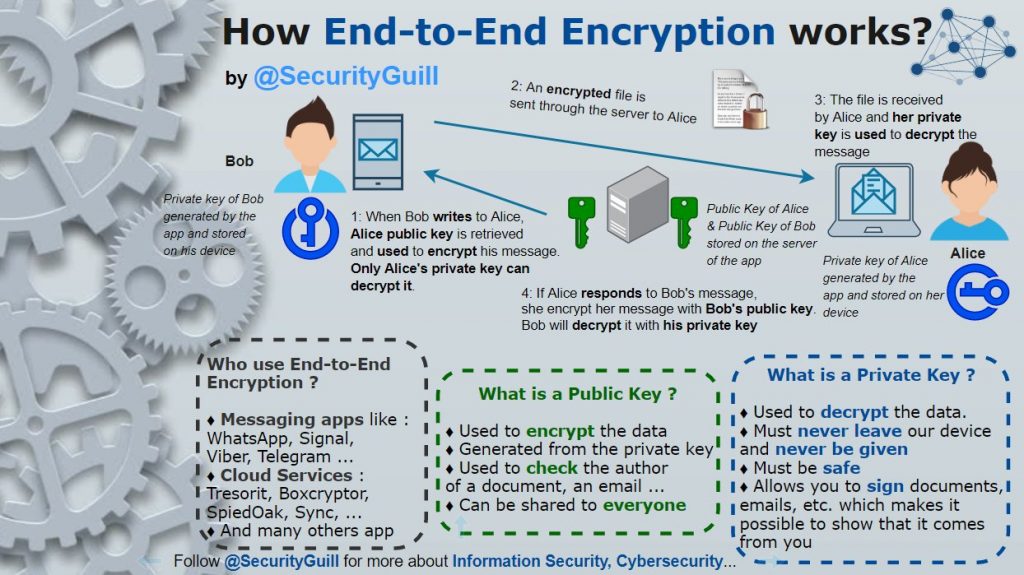
How End-to-End Encryption Works
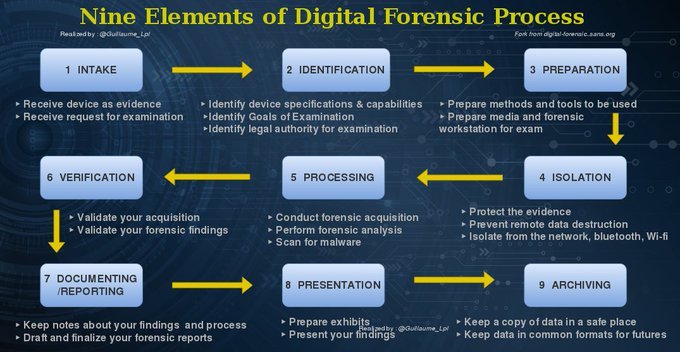
Nine Elements of Digital Forensic Process
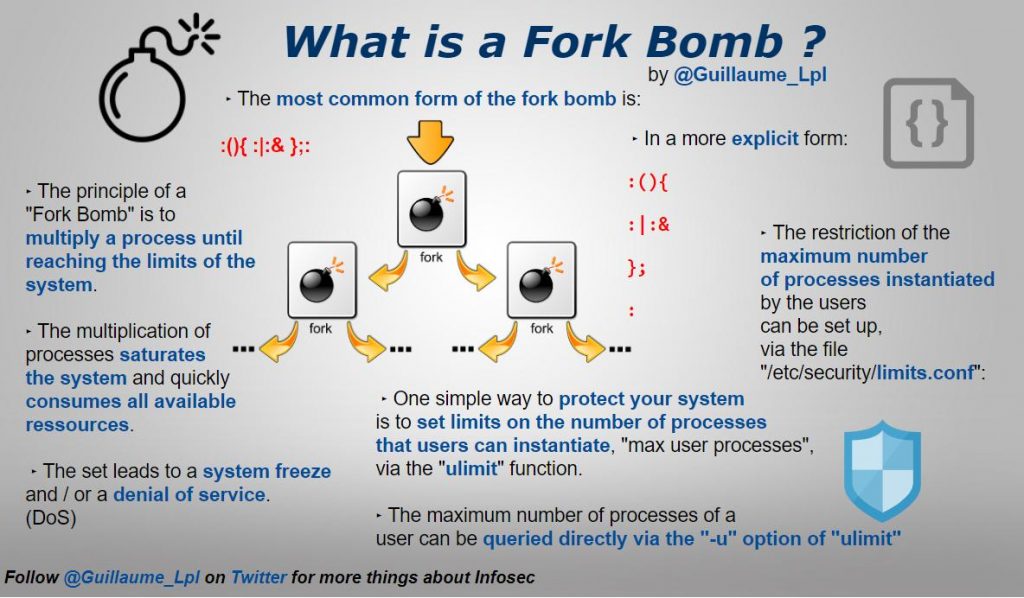
What is a Fork Bomb
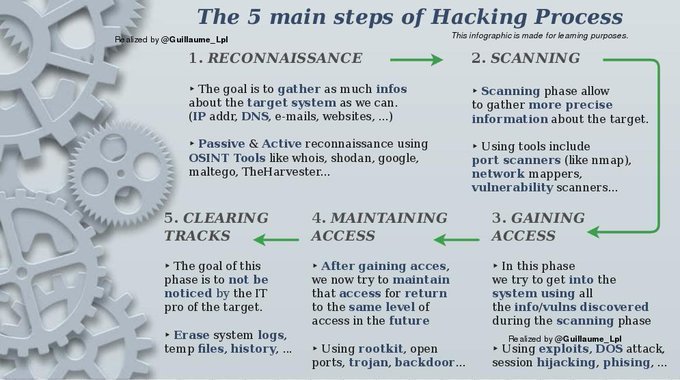
The 5 main steps of Hacking Process
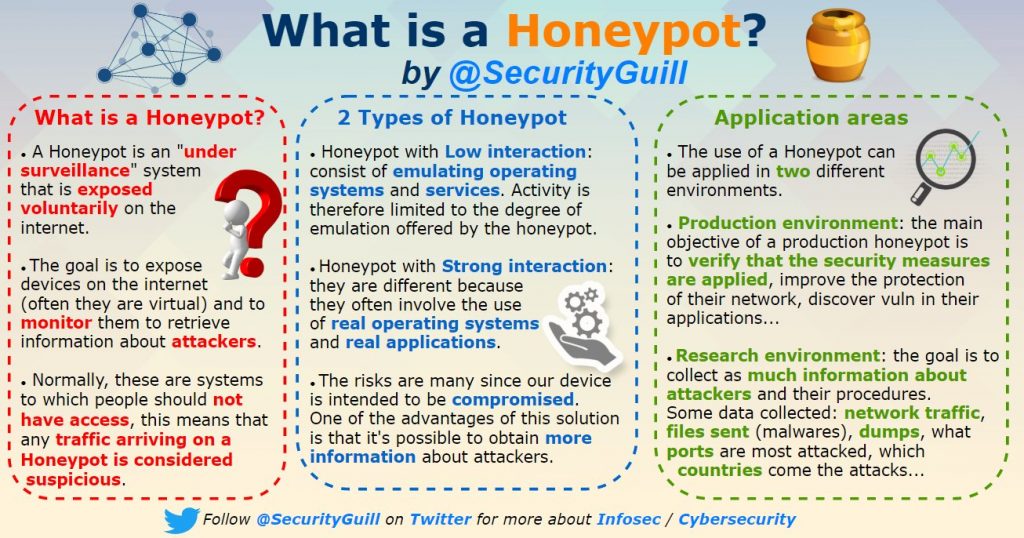
What is a Honeypot
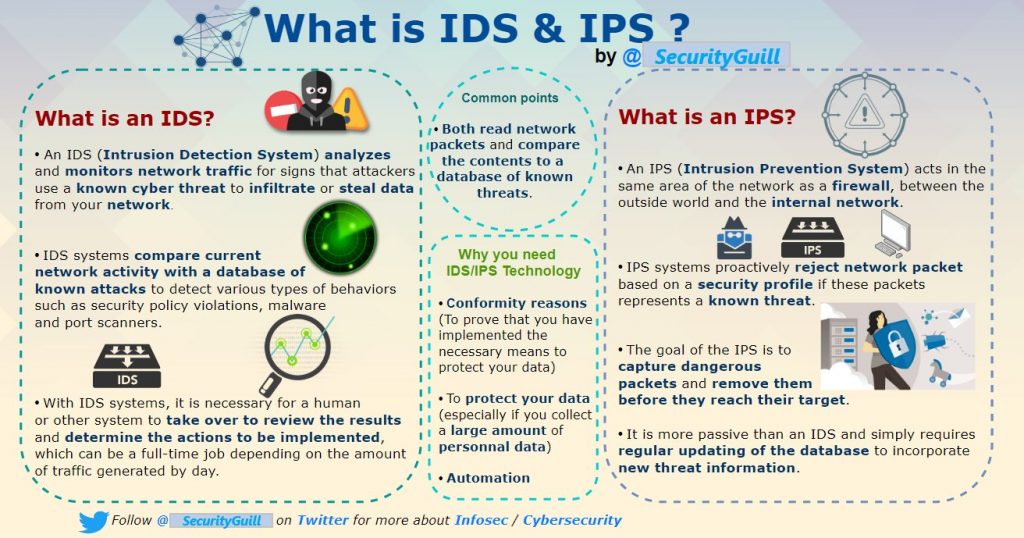
What is IDS & IPS
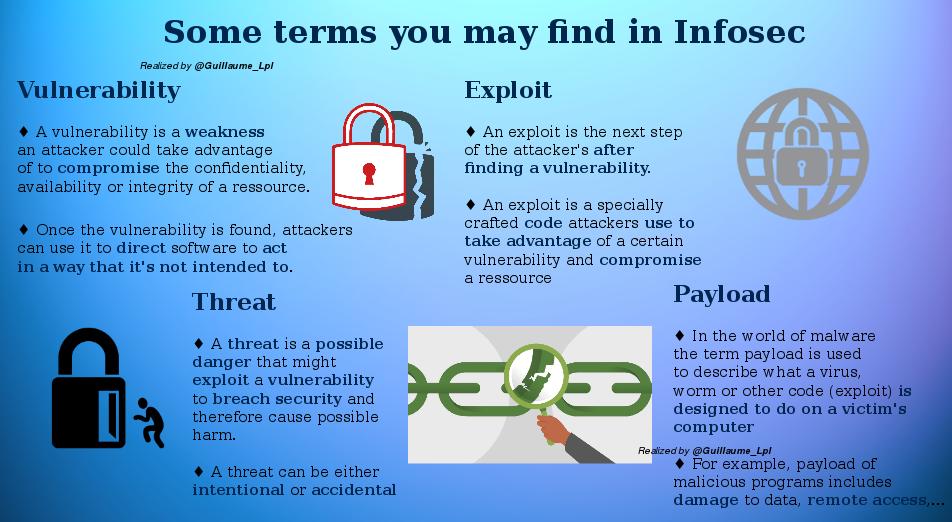
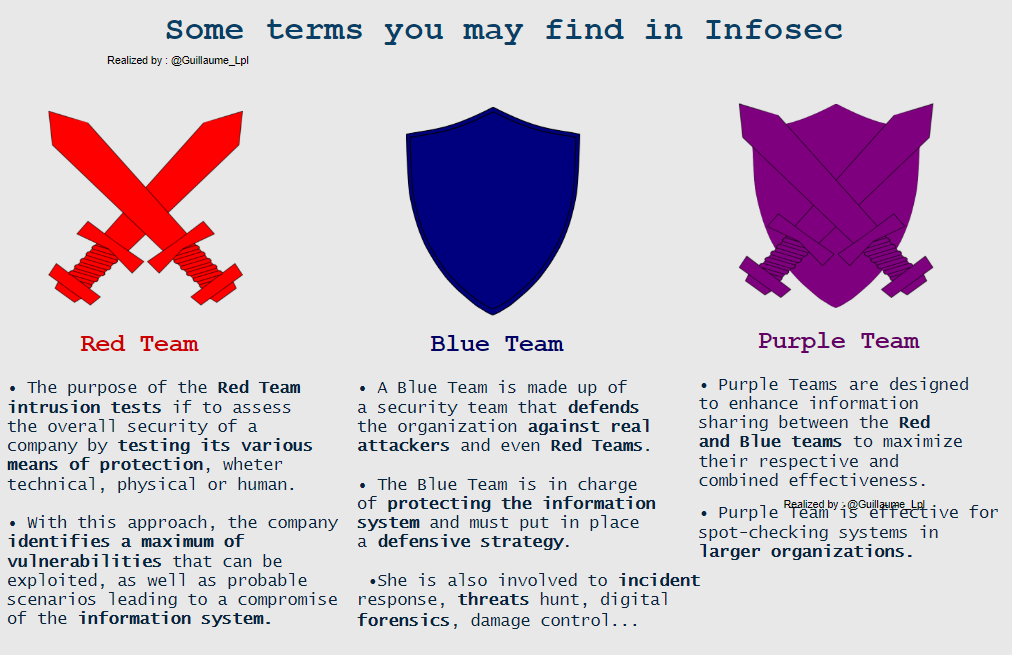
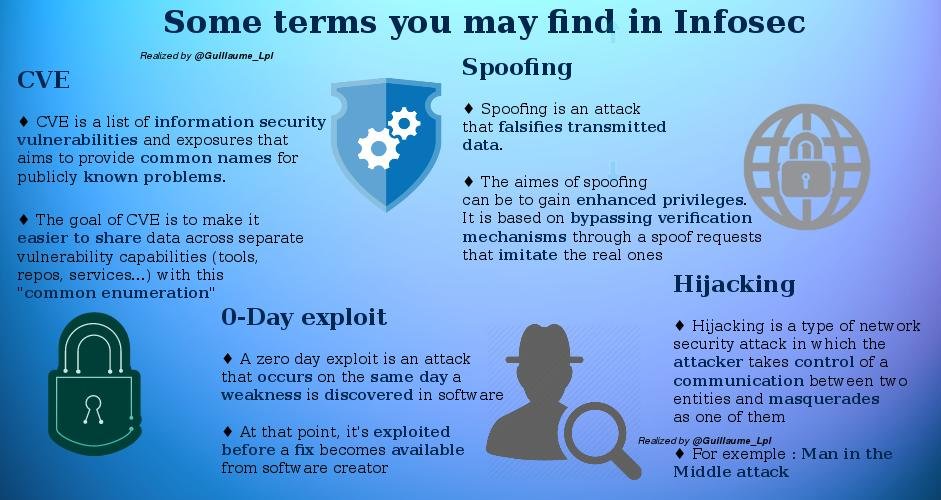
Some infosec Terms

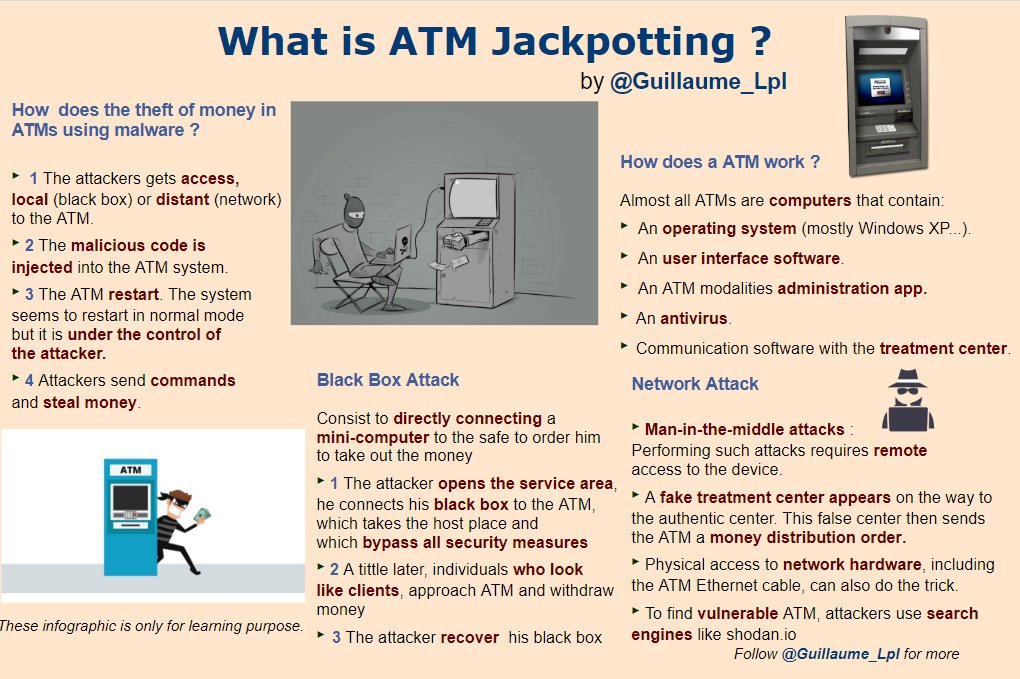
What is Jackpotting
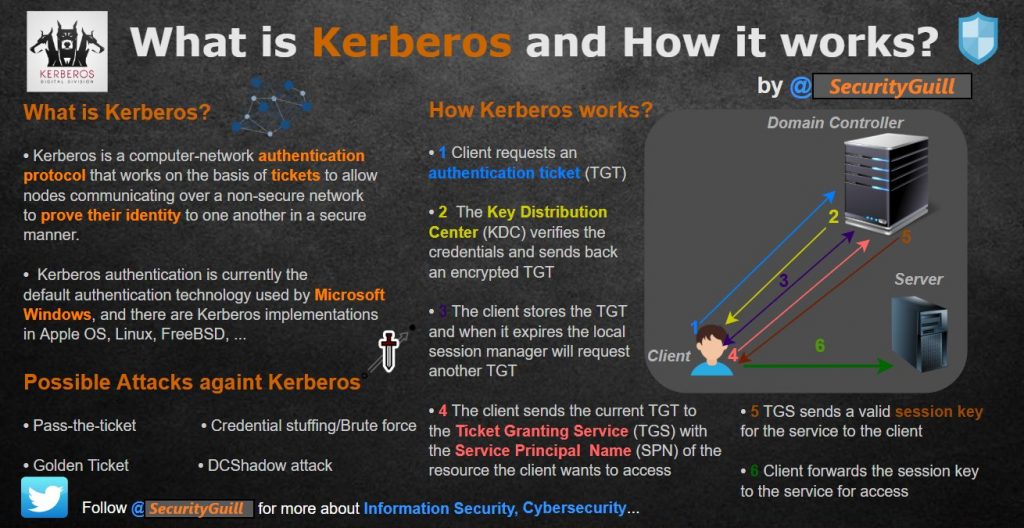
What is Kerberos and How It Works?
What is Kubernetes
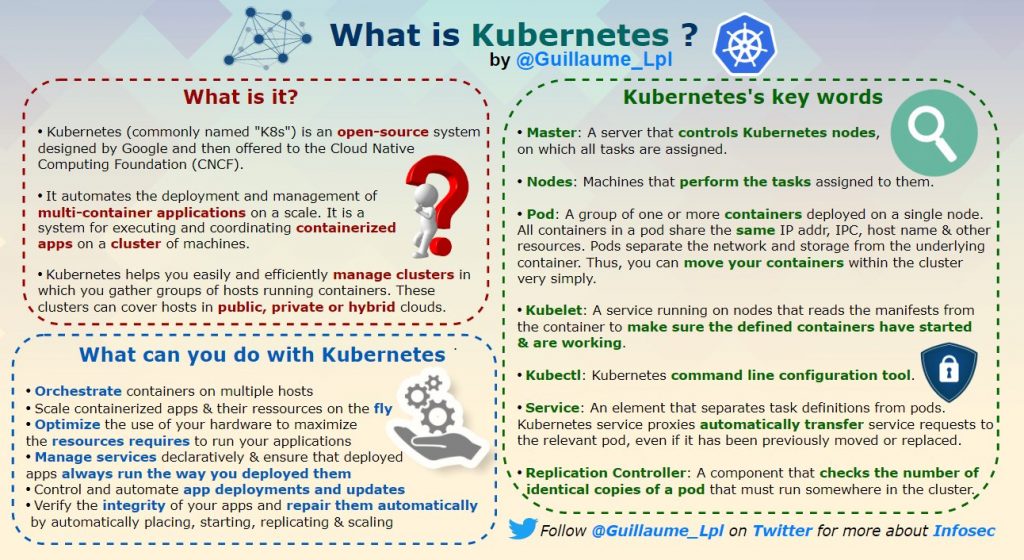
What is LDAP and How It Works?
Some Basic Linux COmmands

What is Metasploit?

What is MFA

What is Mimikatz?

How does Mirai Botnet Works?
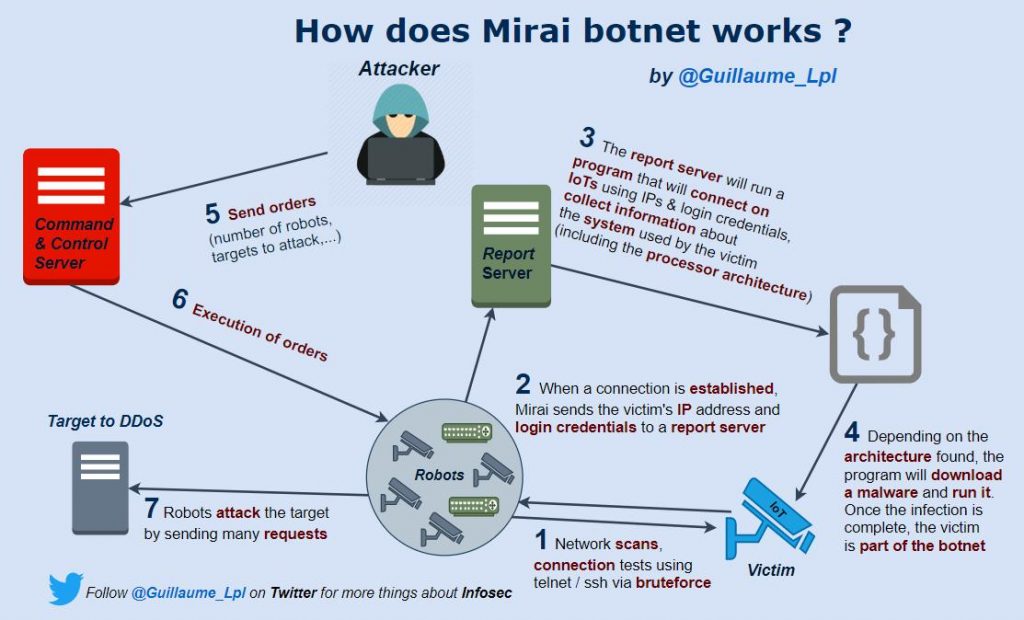
Man in The Middle Attack
What is Nmap


Most Critical Web App Security Risks

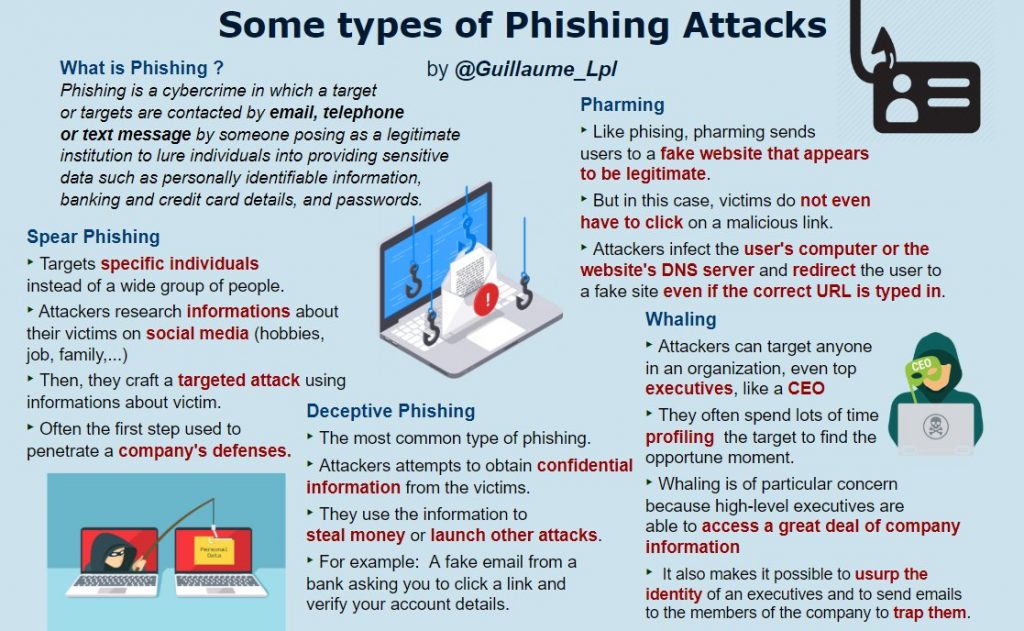
Some types of phishing attacks
The main programming languges in Infosec and their main uses

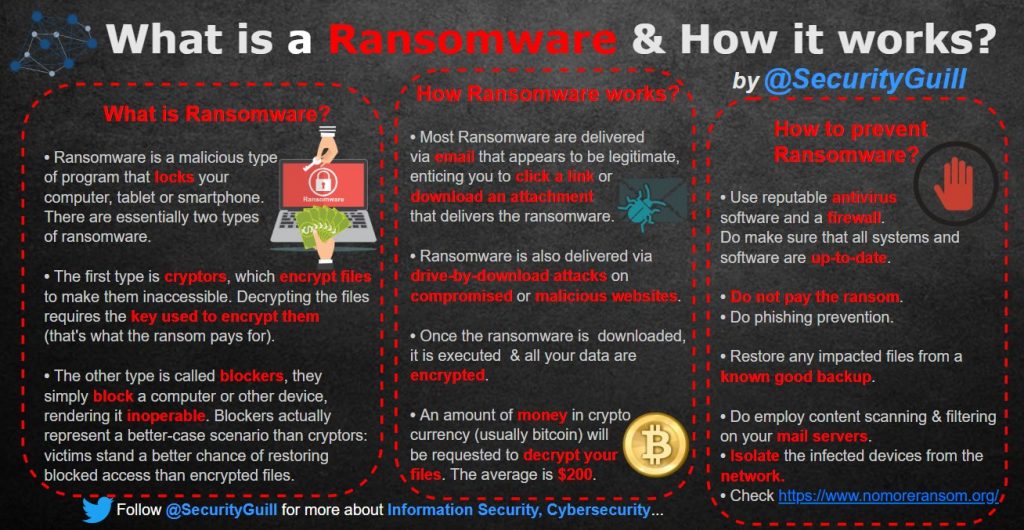
What is ransomware and how it works
Some good practices to avoid social engineering attack

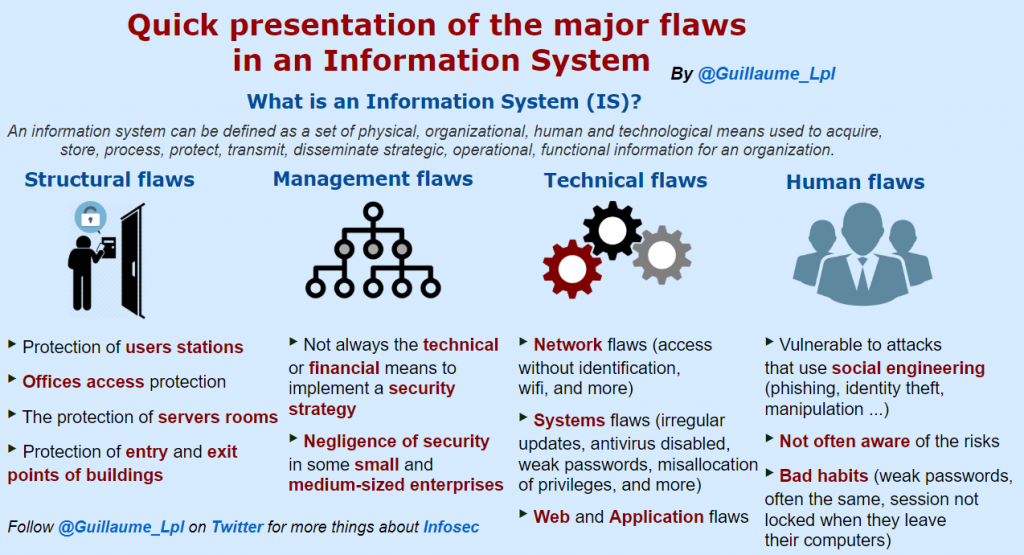
Major flaws in an Information System
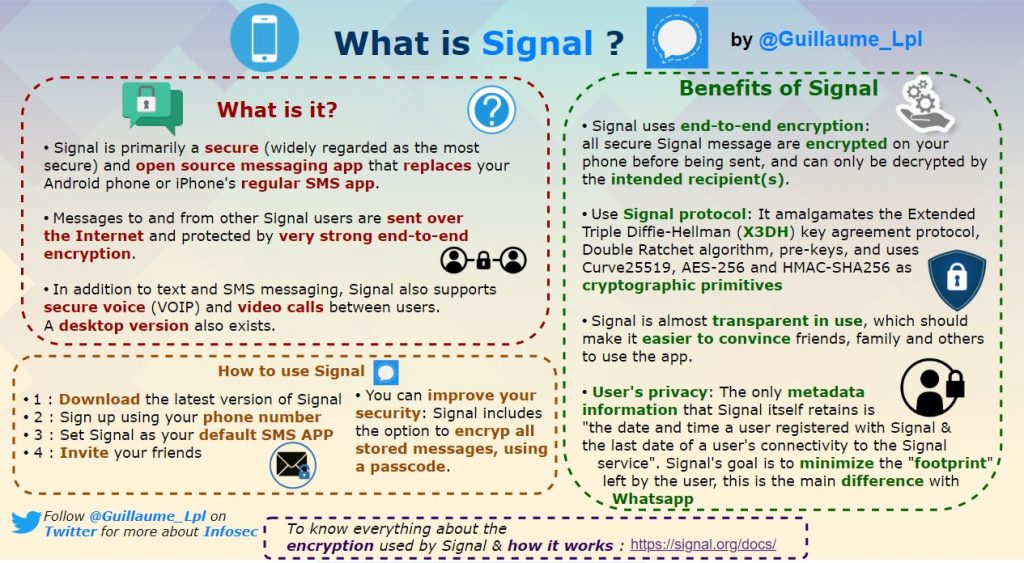
What is Signal
What is Software Reverse Engineering

Tools Useful for Forensic Analysis


Online Tools to analyze vulnerabilities and malware of websites





Tools for OSINT


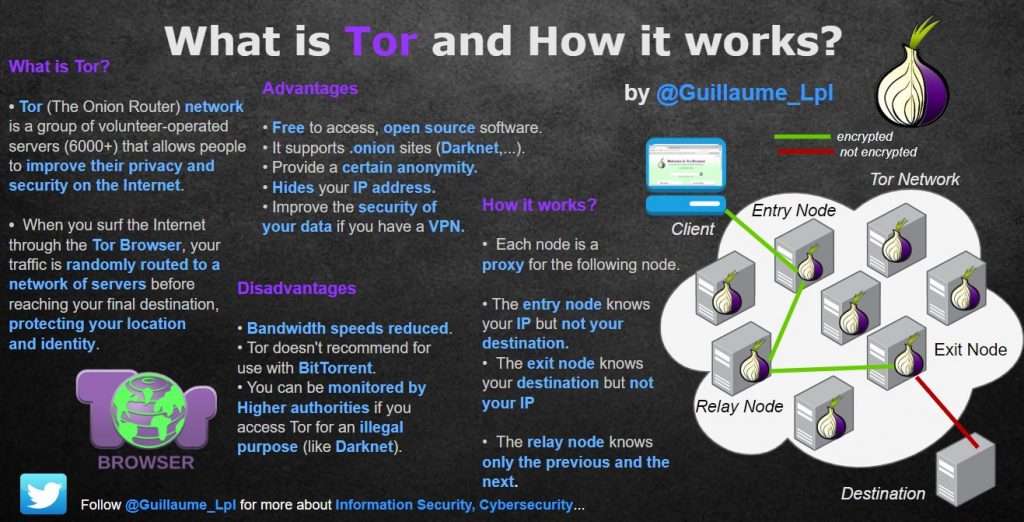
What is TOR and how it works
Vulnerability Scanners


Most common vulnerabilities in web application


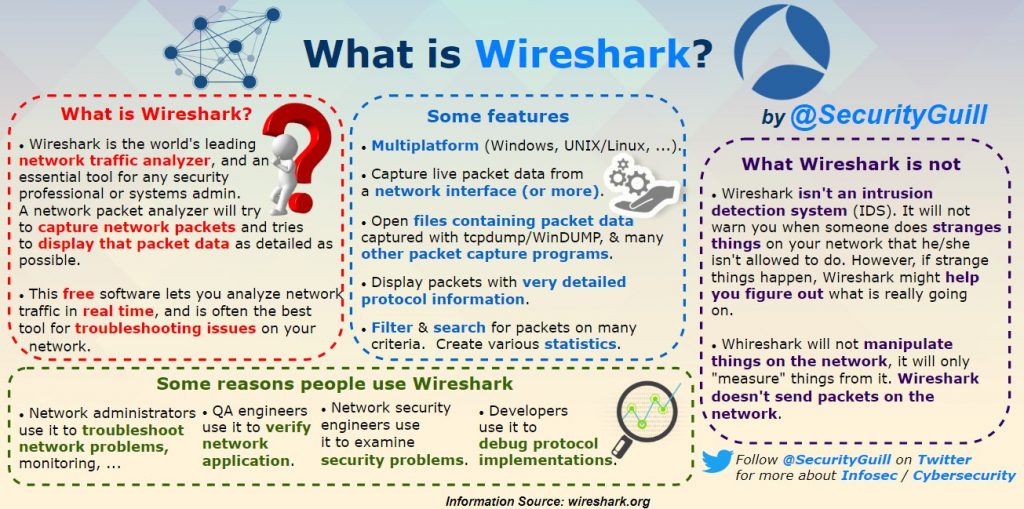
What is Wireshark?
What is XSS attack?

What is Zed Attack Proxy

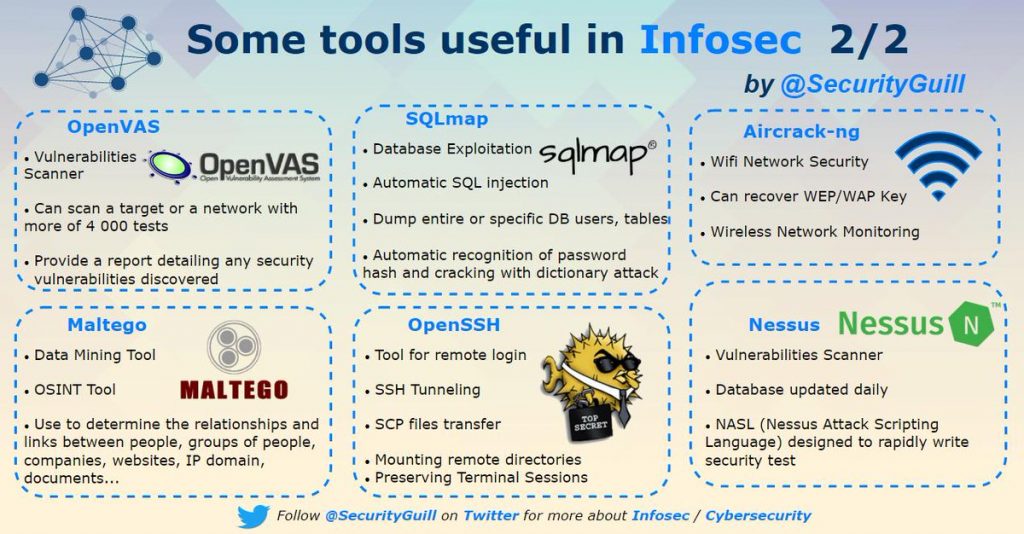
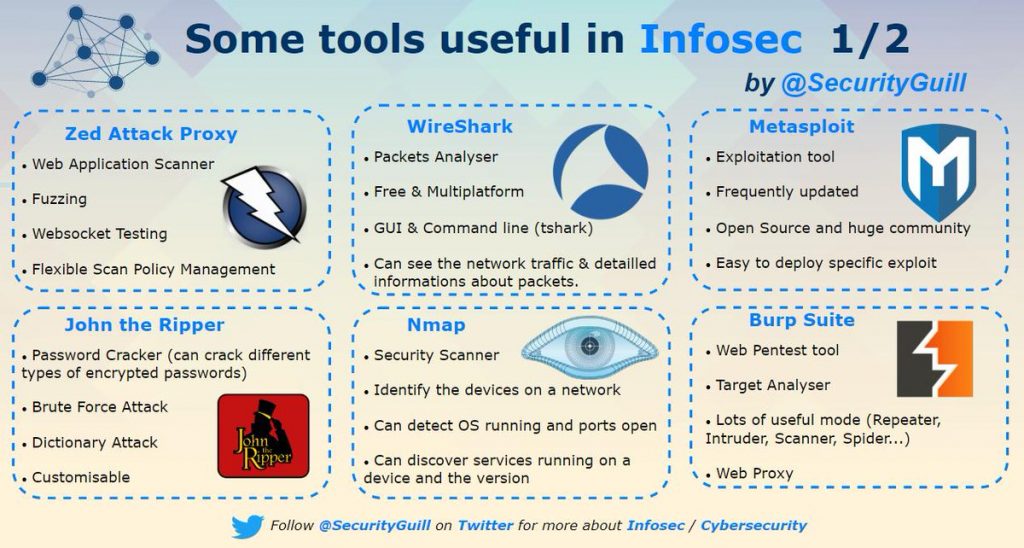
Infosec Tools
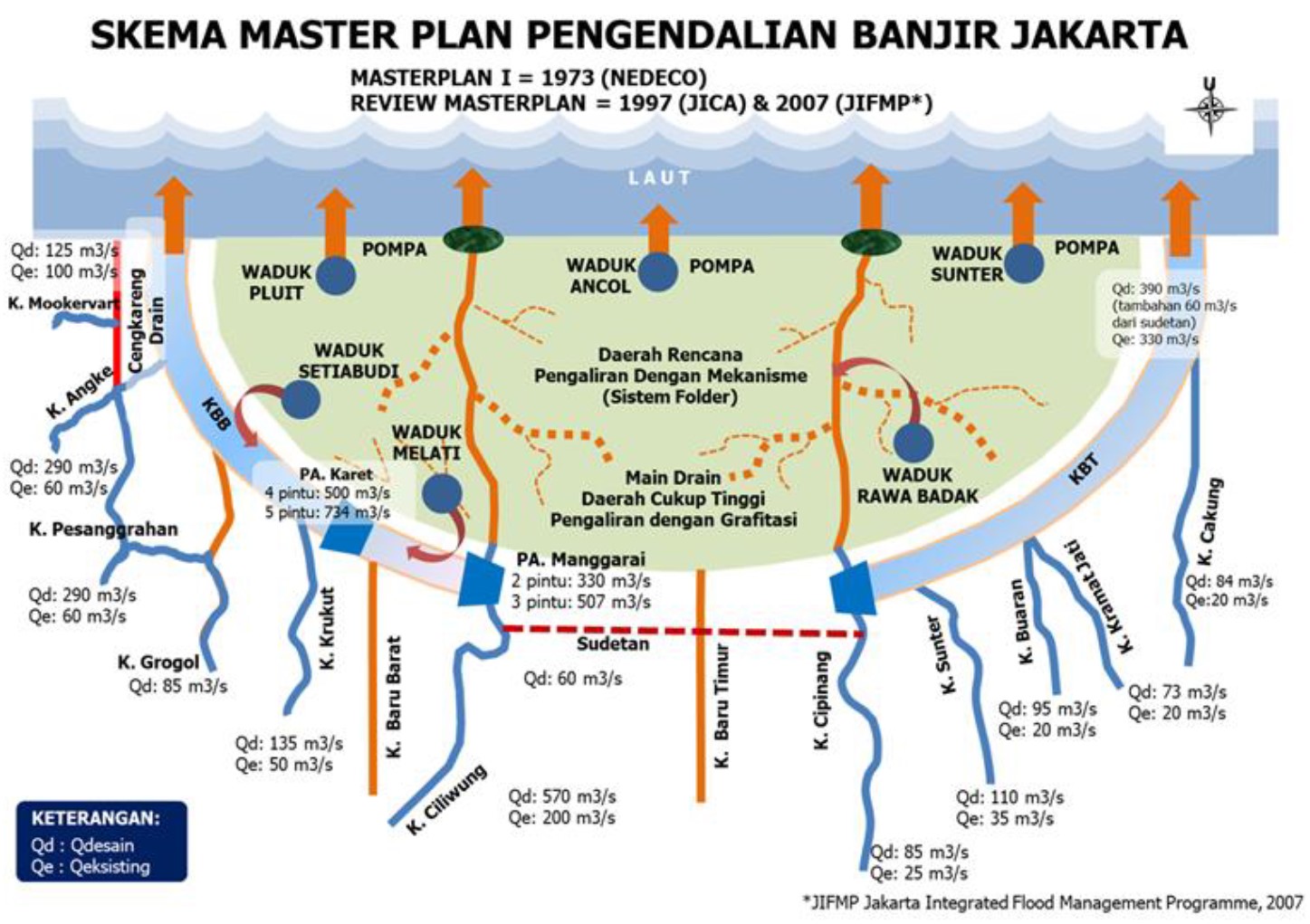
Pengendalian Banjir Jakarta
Master Plan 2020 Menurut PUPR
Berikut ini adalah skema master plan pengendalian banjir Jakarta menurut Kementerian PUPR (Kementerian Pekerjaan Umum dan Perumahan Rakyat)
Gambar di bawah ini adalah presentasi menteri PUPR setelah kasus banjir Januari 2020
Sumber dokumen aslinya dari “Skematik Pengendalian Banjir di DKI Jakarta” , gambar ini juga dirujuk di dokumen Kajian Pengelolaan Banjir DKI dan Sekitarnya Bagi Pembangunan Infrastruktur Berkelanjutan
Pada skema tersebut terdapat angka-angka debit sungai di Jakarta dan sekitarnya. Tidak disebutkan kemampuan drainage ke laut, serta pengaruh pasang surut.
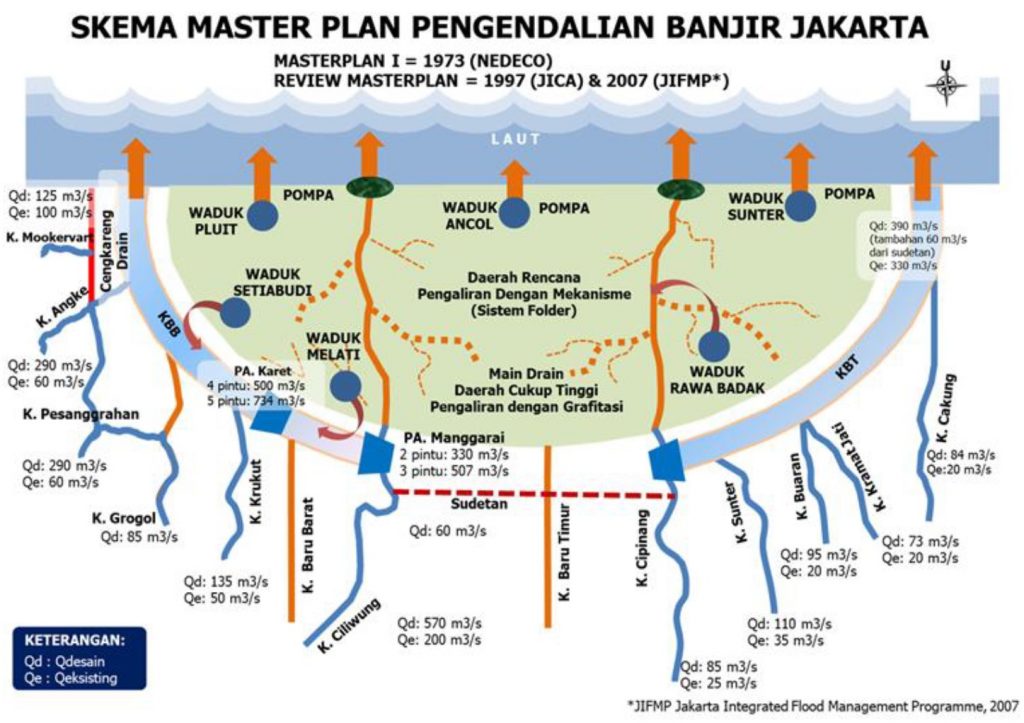
Master Plan 1973
Penjelasan:
- Aliran air dari hulu DKI dialihkan ke Banjir Kanal langsung ke laut
- Aliran di wilayah selatan DKI dengan kontur tanah yang cukup tinggi mengalir secara gravitasi
- Di bagian utara yang rendah aliran air dikelola dengan sistem polder (tanggul, waduk dan pompa)
- Bagian hulu / selatan perlu dibangun / dilestarikan situ-situ, waduk dan penghijauan untuk menahan aliran air ke Jakarta
Hasil dari posting pak Muslim Muin: https://www.facebook.com/muslin.muin/posts/10218250932121467
Referensi
- Kajian Pengelolaan Banjir DKI dan Sekitarnya Bagi Pembangunan Infrastruktur Berkelanjutan, Center for Infrastructure and Built Environment (CIBE) Institut Teknologi Bandung. https://www.itb.ac.id/files/focus/Laporan_Kajian_Banjir_(030320).pdf
- Pengembangan Terpadu Pesisir Ibukota Negara (PTPIN)
- Skematik Pengendalian Banjir di DKI Jakarta
- Penanganan Banjir DKI dan Jabodetabek (2010)
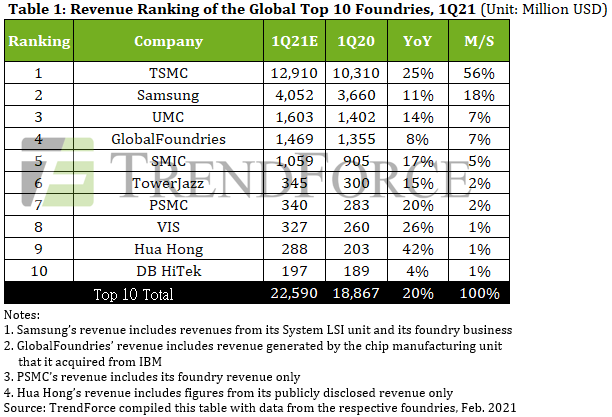
Permintaan Semikonduktor Tinggi, Pendapatan Pabrik Silikon Meningkat
Free Ebook: Mathematics for Machine Learning
Ebook PDF: https://mml-book.github.io/book/mml-book.pdf
Jupyter Notebook: https://github.com/mml-book/mml-book.github.io
Table of Contents
Part I: Mathematical Foundations

- Introduction and Motivation
- Linear Algebra
- Analytic Geometry
- Matrix Decompositions
- Vector Calculus
- Probability and Distribution
- Continuous Optimization
Part II: Central Machine Learning Problems
- When Models Meet Data
- Linear Regression
- Dimensionality Reduction with Principal Component Analysis
- Density Estimation with Gaussian Mixture Models
- Classification with Support Vector Machines

Hardware for Deep Learning
Article from blog.intent.to
- Part 1 : Introduction
- Part 2: CPU
- Part 3: GPU
- Part 4: ASIC
- Part 5: FPGA
- Part 6: Mobile AI
- Part 7: Neuromorphic computing
- Part 8: Quantum computing


Probabilistic Machine Learning: an Introduction
Probabilistic Machine Learning: an Introduction by Kevin P. Murphy
URL: https://probml.github.io/pml-book/book1.html

Membatasi Jumlah Client pada Apache 2.4
Web server Apache akan menjadi lambat / hang jika diakses oleh terlalu banyak client, sedangkan memori sudah habis. Akan terjadi permintaan memory swap yang besar sehingga semuanya akan semakin lambat. Pada akhirnya koneksi akan terputus. Untuk membatasi jumlah client, dapat digunakan setting “MaxRequestWorkers”.
Berikut ini salah satu contoh setting untuk server yang memorynya sedikit.
<IfModule mpm_worker_module>
ServerLimit 5
StartServers 2
MaxRequestWorkers 20
MinSpareThreads 5
MaxSpareThreads 5
ThreadsPerChild 5
</IfModule>