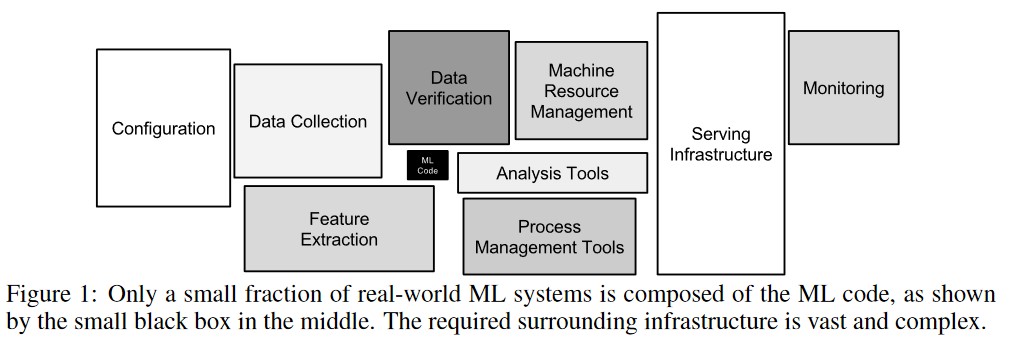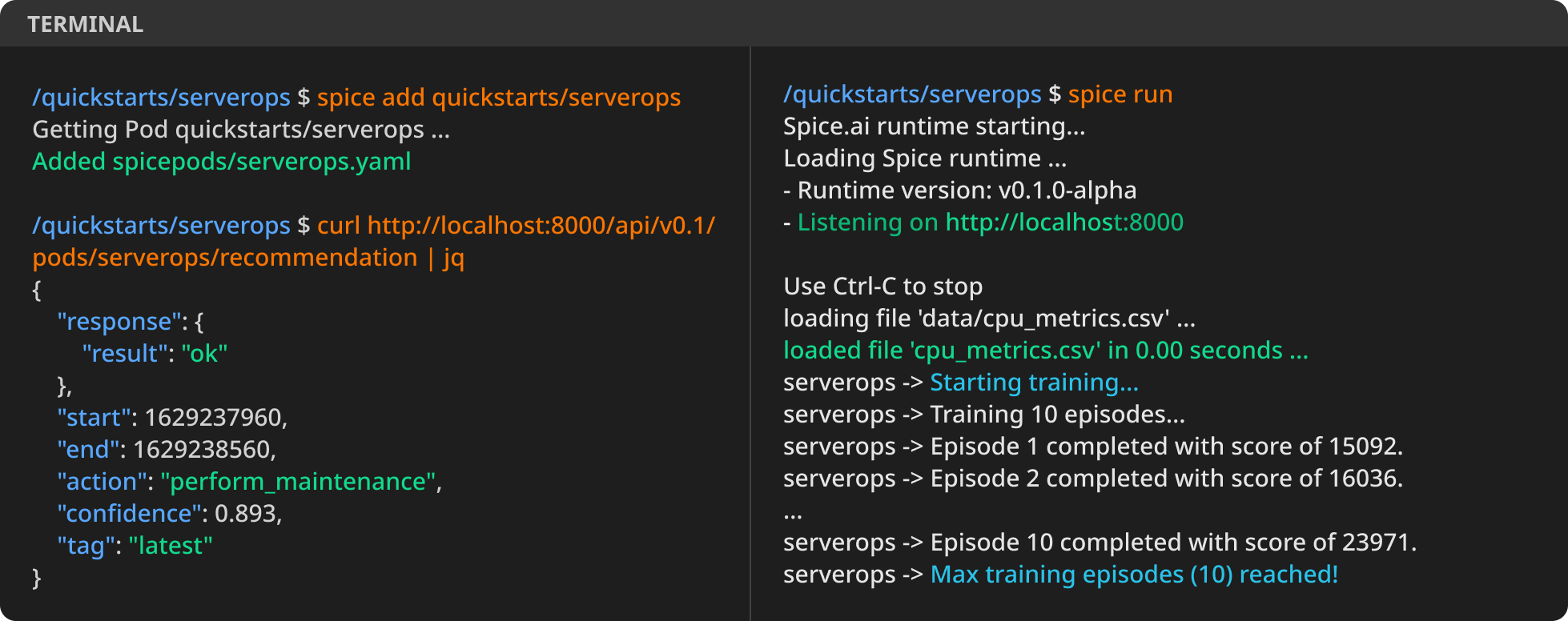
Spice.ai available on GitHub, a new open source project that helps developers use deep learning to create intelligent applications
Spice.ai available on GitHub, a new open source project that helps developers use deep learning to create intelligent applications
Prosedur instalasi Pytorch di Windows:
Saya menggunakan conda, untuk itu di Windows mesti melakukan dulu instalasi Anaconda Individual Edition atau Miniconda

Link: http://databookuw.com/

I believe that the entire dataset (including bounding box for test images) is released here: https://zenodo.org/record/5092309 1
This dataset is mentioned in the new paper “Global Wheat Head Dataset 2021 1” , in the “Code & Data Section”
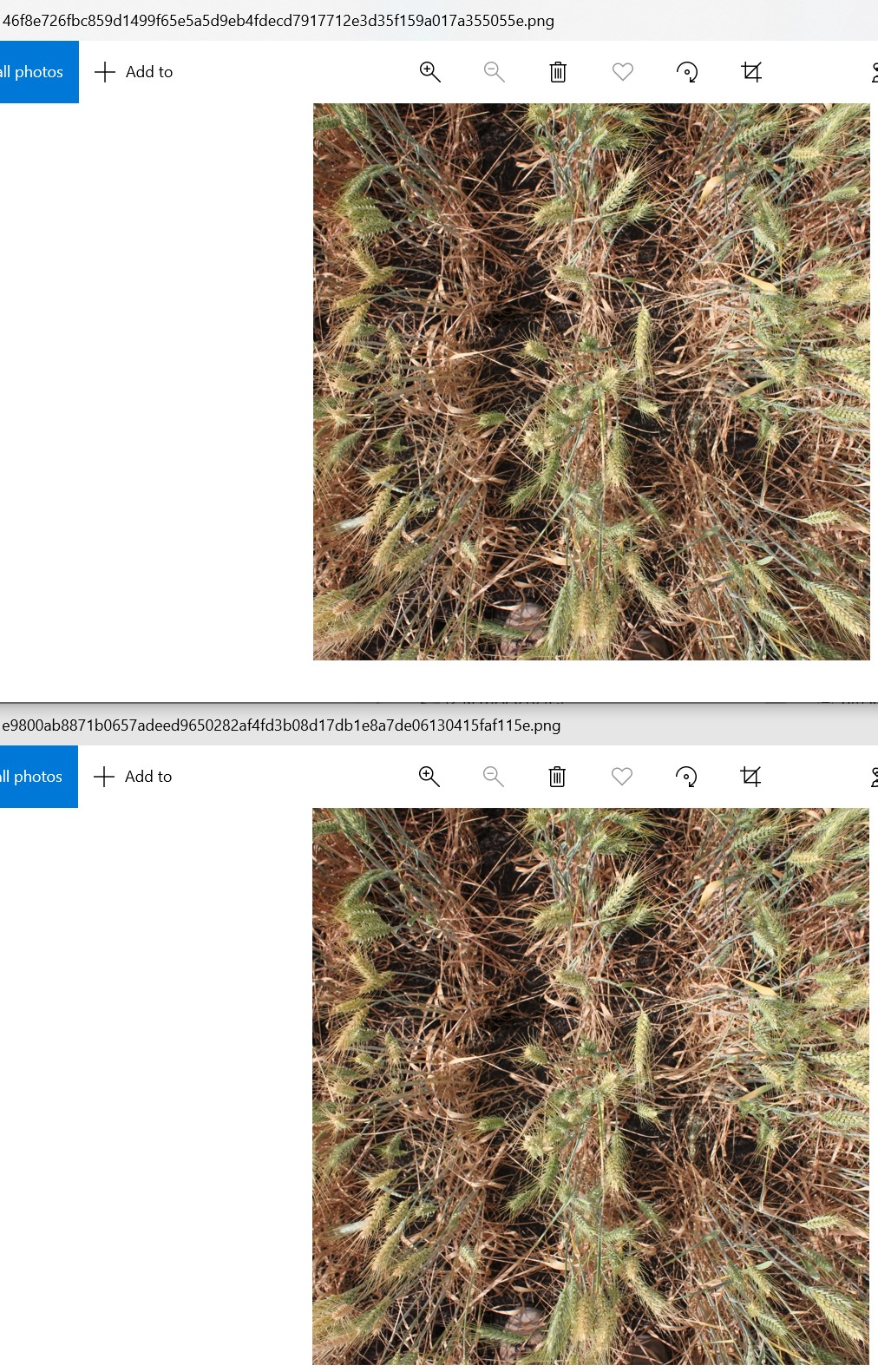
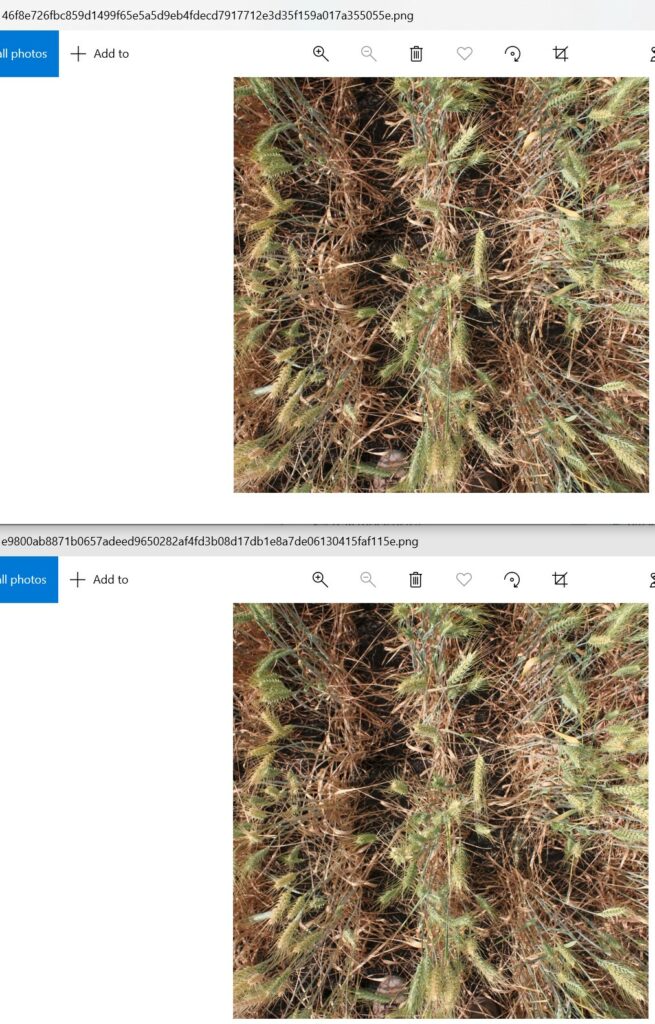
I did a quick look, and I found that image filenames are changed.
Top image: from AIcrowd competition file
Bottom image: from complete dataset
posisi setting setiap VM:
Daftar storage:
Registering LVM Thin:
Datacenter -> Storage -> Add (LVM Thin)
Cek daftar VS
An interesting free ebook
When we developed the course Statistical Machine Learning for engineering students at Uppsala University, we found no appropriate textbook, so we ended up writing our own. It will be published by Cambridge University Press in 2021.
Andreas Lindholm, Niklas Wahlström, Fredrik Lindsten, and Thomas B. Schön
A draft of the book is available below. We will keep a PDF of the book freely available also after its publication.
Latest draft of the book (older versions >>)

Source: https://ai.googleblog.com/2021/07/speeding-up-reinforcement-learning-with.html
Reinforcement learning (RL) is a popular method for teaching robots to navigate and manipulate the physical world, which itself can be simplified and expressed as interactions between rigid bodies1 (i.e., solid physical objects that do not deform when a force is applied to them). In order to facilitate the collection of training data in a practical amount of time, RL usually leverages simulation, where approximations of any number of complex objects are composed of many rigid bodies connected by joints and powered by actuators. But this poses a challenge: it frequently takes millions to billions of simulation frames for an RL agent to become proficient at even simple tasks, such as walking, using tools, or assembling toy blocks.

Original Competition: https://www.kaggle.com/c/noaa-fisheries-steller-sea-lion-population-count
Best solutions:
Related Articles