Istilah ‘chipageddon’ diperkenalkan oleh orang yang biasa berkecimpung di industri mikroelektronika sebagai sebutan untuk masalah kekurangan pasokan mikrochip yang akhir-akhir ini (tahun 2020 ~ 2021) terjadi. Istilah ini adalah lakuran dari ‘microchip’ dan ‘armageddon‘
Istilah chipageddon ini memang agak berlebihan, karena armageddon kurang lebih artinya bencana besar di akhir zaman, sedangkan kekurangan pasokan microchip ini hanya menyebabkan kehidupan lebih repot, namun tidak sampai membuat kehidupan dunia berakhir.
Microchip adalah rangkaian elektronik yang digabungkan pada suatu keping kecil (‘chip’) bahan semikonduktor. Bahan semikonduktor yang paling umum dipakai adalah silikon. Microchip dikenal juga sebagai sirkuit terpadu (‘Integrated Circuit‘) atau IC.
Kualitas ventilasi ruangan adalah salah satu faktor penting untuk mengurangi penularan COVID-19. Transmisi virus SARS-CoV-2 dapat melalui droplet maupun aerosol. Droplet dimensinya agak besar, sehingga terbangnya tidak terlalu jauh. Aerosol dapat terbang cukup jauh, sehingga jarak 2 meter tidak cukup aman.
Untuk mengurangi penularan maka udara di suatu ruangan harus sering diganti baru atau dibersihkan dengan filter.
Ukuran kualitas ventilasi yang sering dipakai ada 2 yaitu debit aliran udara per detik dan ACH (Air Changes per Hour).
Debit aliran udara yang dipakai adalah 10 liter per orang per detik. [1]
Angka ACH yang dipakai minimal adalah 4, kalau bisa mencapai 6 [2].
Pada artikel ini dibahas pengukuran ACH dengan sensor debu.
Prinsip Pengukuran
Virus bersifat sebagai aerosol. Aerosol disimulasikan dengan menggunakan kabut yang dibangkitkan dengan alat fog generator. Kabut ini akan meningkatkan jumlah debu dalam ruangan.
Keberadaan kabut dideteksi oleh sensor debu.
Ventilasi diaktifkan untuk mengganti udara dengan udara segar yang bersih tidak mengandung debu. Jika udara sudah berhasil diganti, maka angka debu di sensor akan turun kembali ke keadaan normal.
Peralatan
Peralatan yang diperlukan adalah sebagai berikut
Pembangkit kabut / fog generator
Alat ukur debu. Misalnya menggunakan sensor GP2Y10 yang dihubungkan ke mikroproser Arduino Nano. Detail pembuatan dibahas di artikel tersendiri.
Laptop , mikroprosesor Arduino Nano dan sensor debu GP2Y10
Pembangkit kabut (fog generator)
Alternatif lain menggunakan perangkat handheld particle counter. Alat ini lebih bagus/presisi, namun juga lebih mahal. Pada pengukuran ini tidak diperlukan angka absolut jumlah debu, jadi pakai sensor murah juga sudah cukup.
Handheld particle counter
Prosedur pengukuran
Nyalakan sensor debu
Pastikan angka debu yang terukur stabil selama sekurang-kurangnya 10 menit. Angka ini akan dijadikan referensi keadaan ‘bersih’
Nyalakan fog generator untuk membuat kabut. Isi ruangan dengan kabut sampai cukup banyak
Tunggu sampai kabut hilang.
Hentikan pengukuran setelah kabut sudah tidak terlihat, atau sudah cukup lama
Lakukan analisis untuk menghitung berapa lama waktu yang diperlukan agar kabut hilang
Pembangkit kabut sedang bekerja
Berikut ini percobaan pengkabutan di laboratorium
Analisis
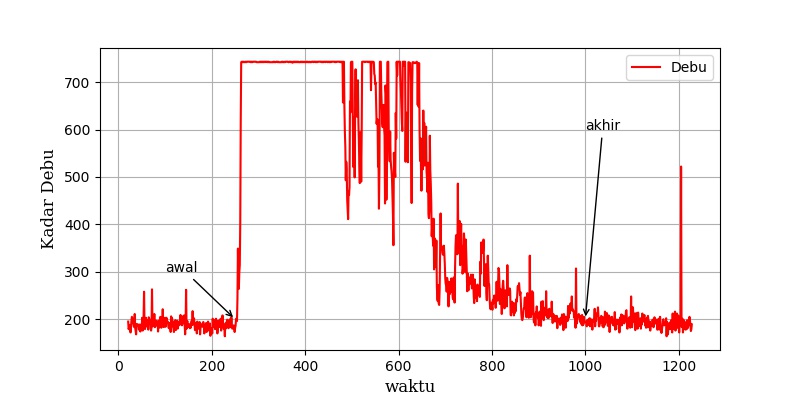
Berikut ini contoh grafik jumlah debu terhadap waktu.
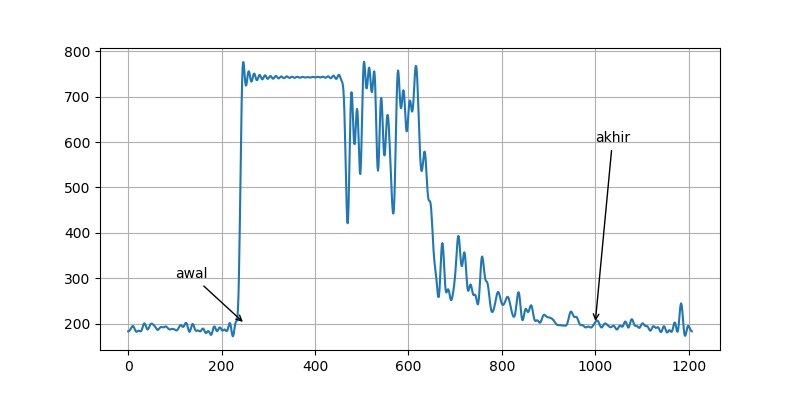
Kurva jumlah debu terhadap waktu masih banyak noise nya sehingga agak sulit melakukan analisis. Berikut ini sinyal yang sama namun dengan filter supaya sinyal frekuensi tinggi dihilangkan.
Dari kurva tersebut nampak bahwa debu mulai masuk di t=200, dan sudah hilang di sekitar t=1000. Jadi perlu waktu 800 detik untuk mengganti udara yang berkabut sampai bersih dengan udara baru.
Nilai ACH = 60 x 60 / 800 = 4,5
Jadi ruangan ini dalam 1 jam dapat melakukan pergantian udara sebanyak 4,5 kali.
A Ryzen 5 5600X processor produces the following error message:
kernel:[920812.434956] [Hardware Error]: Corrected error, no action required.
Message from syslogd@b550 at Jun 9 04:51:14 ...
kernel:[920812.441570] [Hardware Error]: CPU:1 (19:21:0) MC15_STATUS[Over|CE|-|-|-|-|-|-|-]: 0xc04100a49b07c7cb
Message from syslogd@b550 at Jun 9 04:51:14 ...
kernel:[920812.447096] [Hardware Error]: IPID: 0x0000000000000000
Message from syslogd@b550 at Jun 9 04:51:14 ...
kernel:[920812.451923] [Hardware Error]: Microprocessor 5 Unit Ext. Error Code: 7, Instruction Cache Bank B ECC or parity error.
Message from syslogd@b550 at Jun 9 04:51:14 ...
kernel:[920812.456683] [Hardware Error]: cache level: L3/GEN, tx: GEN
Berikut ini perintah untuk mengetahui daftar DNS server yang dipakai oleh Ubuntu 20.04, dari command line:
systemd-resolve --status
Outputnya kurang lebih seperti ini:
Global
LLMNR setting: no
MulticastDNS setting: no
DNSOverTLS setting: no
DNSSEC setting: no
DNSSEC supported: no
DNSSEC NTA: 10.in-addr.arpa
16.172.in-addr.arpa
168.192.in-addr.arpa
17.172.in-addr.arpa
18.172.in-addr.arpa
19.172.in-addr.arpa
20.172.in-addr.arpa
21.172.in-addr.arpa
22.172.in-addr.arpa
23.172.in-addr.arpa
24.172.in-addr.arpa
25.172.in-addr.arpa
26.172.in-addr.arpa
27.172.in-addr.arpa
28.172.in-addr.arpa
29.172.in-addr.arpa
30.172.in-addr.arpa
31.172.in-addr.arpa
corp
d.f.ip6.arpa
home
internal
intranet
lan
local
private
test
Link 2 (enp0s31f6)
Current Scopes: DNS
DefaultRoute setting: yes
LLMNR setting: yes
MulticastDNS setting: no
DNSOverTLS setting: no
DNSSEC setting: no
DNSSEC supported: no
Current DNS Server: 111.95.141.4
DNS Servers: 202.73.99.2
118.136.64.5
111.95.141.4
DNS Domain: domain.name
CovidGAN: Data Augmentation Using Auxiliary Classifier GAN for Improved Covid-19 Detection – in this research, we present a method to generate synthetic chest X-ray (CXR) images by developing an Auxiliary Classifier Generative Adversarial Network (ACGAN) based model called CovidGAN. In addition, we demonstrate that the synthetic images produced from CovidGAN can be utilized to enhance the performance of CNN for COVID-19 detection. Classification using CNN alone yielded 85% accuracy. By adding synthetic images produced by CovidGAN, the accuracy increased to 95%. We hope this method will speed up COVID-19 detection and lead to more robust systems of radiology.
Iteratively Pruned Deep Learning Ensembles for COVID-19 Detection in Chest X-rays – The best performing models are iteratively pruned to reduce complexity and improve memory efficiency. The predictions of the best-performing pruned models are combined through different ensemble strategies to improve classification performance. Empirical evaluations demonstrate that the weighted average of the best-performing pruned models significantly improves performance resulting in an accuracy of 99.01% and area under the curve of 0.9972 in detecting COVID-19 findings on CXRs. The combined use of modality-specific knowledge transfer, iterative model pruning, and ensemble learning resulted in improved predictions. We expect that this model can be quickly adopted for COVID-19 screening using chest radiographs.
COVID-ResNet: A Deep Learning Framework for Screening of COVID19 from Radiographs – Using these techniques, we showed the state of the art results on the open-access COVID-19 dataset. This work presents a 3-step technique to fine-tune a pre-trained ResNet-50 architecture to improve model performance and reduce training time. We call it COVIDResNet. This is achieved through progressively re-sizing of input images to 128x128x3, 224x224x3, and 229x229x3 pixels and fine-tuning the network at each stage. This approach along with the automatic learning rate selection enabled us to achieve the state of the art accuracy of 96.23% (on all the classes) on the COVIDx dataset with only 41 epochs. This work presented a computationally efficient and highly accurate model for multi-class classification of three different infection types from along with Normal individuals. This model can help in the early screening of COVID19 cases and help reduce the burden on healthcare systems.
More Papers (from https://www.kaggle.com/c/siim-covid19-detection/discussion/240838)
The above is a link to a peer-reviwed paper recently published in the prestigious journal Nature Machine Intelligence. They examined 2,212 studies published in 2020, of which 415 were included after initial screening and, after quality screening, 62 studies were included in the systematic review.
Unfortunately they found that “…none of the models identified are of potential clinical use due to methodological flaws and/or underlying biases.“
Their main findings were:
Duplication and quality issues: Source issues, Frankenstein datasets, Implicit biases in the source data
Methodology issues: “…Diagnostic studies commonly compare their models’ performance to that of RT–PCR. However, as the ground-truth labels are often determined by RT–PCR, there is no way to measure whether a model outperforms RT–PCR from accuracy, sensitivity or specificity metrics alone. Ideally, models should aim to match clinicians using all available clinical and radiomic data…”
They then proceed to suggest a number of recommendations. The paper is well worth reading and is Open Access:
Classification: classify whether an image in related with pneumothorax or not. Multi-task model based on UNET (seresnext 50, seresnext101, efficientnet-b3 ) with a branch for classifying. BCE + focal loss. Basic augmentation: hflip, scale, rotate, bright, blur
Segmentation: 2 base models: unet and deeplabv3. Loss: dice loss. Augmentation: same as classification
Unveiling COVID-19 from Chest X-ray with deep learning: a hurdles race with small data Enzo Tartaglione, Carlo Alberto Barbano, Claudio Berzovini, Marco Calandri, Marco Grangetto https://arxiv.org/abs/2004.05405
A Critic Evaluation of Methods for COVID-19 Automatic Detection from X-Ray Images Gianluca Maguolo, Loris Nanni, https://arxiv.org/abs/2004.12823
Pembersih udara buatan MiPembersih udara buatan Trusens
Sharp mengeluarkan produk pembersih udara dengan teknologi plasma cluster, namun teknologi ini dan teknologi sejenis sperti bipolar ionization (BPI) masih menjadi perdebatan.