Readability Assessment for Text Simplification – We describe a readability assessment approach to support the process of text simplification for poor literacy readers. Given an input text, the goal is to predict its readability level, which corresponds to the literacy level that is expected from the target reader: rudimentary, basic or advanced.
Integrating LSA-based hierarchical conceptual space and machine learning methods for leveling the readability of domain-specific texts – Text readability assessment is a challenging interdisciplinary endeavor with rich practical implications. It has long drawn the attention of researchers internationally, and the readability models since developed
have been widely applied to various fields. Previous readability models have only made use of linguistic features employed for general text analysis and have not been sufficiently accurate when used to gauge domain-specific texts.
Deep Learning for Prominence Detection in Children’s Read Speech – A previous well-tuned random forest ensemble predictor is replaced by an RNN sequence classifier to exploit potential context dependency across the longer utterance. Further, deep learning is applied to obtain word-level features from low-level acoustic contours of fundamental frequency, intensity and spectral shape in an end-to-end fashion. Performance comparisons are presented across the different feature types and across different feature learning architectures for prominent word prediction to draw insights wherever possible.
Zhigang Dai, Bolun Cai, Yugeng Lin, Junying Chen, UP-DETR: Unsupervised Pre-training for Object Detection with Transformers – The model is pre-trained to detect these query patches from the original image. During the pre-training, we address two critical issues: multi-task learning and multi-query localization. (1) To trade-off multi-task learning of classification and localization in the pretext task, we freeze the CNN backbone and propose a patch feature reconstruction branch which is jointly optimized with patch detection. (2) To perform multi-query localization, we introduce UP-DETR from single-query patch and extend it to multi-query patches with object query shuffle and attention mask.
Strawberry Detection Using a Heterogeneous Multi-Processor Platform. This paper proposes using the You Only Look Once version 3 (YOLOv3) Convolutional Neural Network (CNN) in combination with utilising image processing techniques for the application of precision farming robots targeting strawberry detection, accelerated on a heterogeneous multiprocessor platform. The results show a performance acceleration by five times when implemented on a Field-Programmable Gate Array (FPGA) when compared with the same algorithm running on the processor side with an accuracy of 78.3\% over the test set comprised of 146 images.
Bag of Freebies for Training Object Detection Neural Networks [paperswithcode] In this works, we explore training tweaks that apply to various models including Faster R-CNN and YOLOv3. These tweaks do not change the model architectures, therefore, the inference costs remain the same. Our empirical results demonstrate that, however, these freebies can improve up to 5% absolute precision compared to state-of-the-art baselines.
Berikut ini perbandingan parameter-parameter penting SSD NVMe dengan kapasitas 1 TB, dengan interface M.2.
SSD WD Blue SN550 NVMe
Tipe-tipe yang dipilih pada tabel berikut ini adalah yang tersedia di pasaran pada bulan April 2021.
Data terutama diperoleh dari situs resmi pabrikan masing-masing SSD. Beberapa produk tidak menyertakan TBW (Terabytes Written) di situsnya, sehingga data TBW perlu dicari dari situs review terkait.
EPROM chip (Erasable Programmable Read Only Memory)
Berikut ini model-model bisnis perusahaan semikonduktor di dunia pada saat ini (2021):
IDM (Integrated Device Manufacturer)
Foundry
Fabless
Fabless
Fabless adalah perusahaan semikonduktor yang membuat dan menjual produk berbasis komponen semikonduktor, namun tidak melakukan fabrikasi sendiri komponen semikonduktornya. Komponen semikonduktor dibuat di pabrik lain (foundry).
Contoh perusahaan yang melakukan fabless:
Qualcomm
Nvidia
AMD
Mediatek
Integrated Device Manufacturer (IDM)
IDM (Integrated Device Manufacturer) adalah perusahaan semikonduktor yang melakukan desain (perancangan), manufakturing (fabrikasi) dan menjual produk rangkaian terintegrasi (IC/Integrated Circuit)
Salah satu media penularan penyakit COVID-19 adalah melalui virus yang terlarut di udara sebagai aerosol.
Partikel virus yang besar (droplet) akan cepat jatuh dan menempel ke permukaan. Untuk mencegah penularan dari partikel ini ini dapat dilakukan hal berikut:
mencuci tangan dengan sabun atau hand sanitizer
tidak menyentuh wajah dengan tangan
membunuh virus dengan cahaya ultraviolet,
membunuh virus dengan desinfektan anti virus
Untuk mengurangi penularan melalui aerosol ini dapat menggunakan antara lain:
masker wajah (face-mask)
Penyaringan udara dengan saringan HEPA atau pembersih udara lainnya.
penyinaran udara dengan cahaya ultra violet
Ventilasi ruangan yang baik, supaya konsentrasi virus rendah
Standar ventilasi antara lain dikeluarkan oleh WHO (World Health Organization) dan CDC (Centers for Disease Control and Prevention).
Level A: a CO2 concentration lower than 900 ppm (parts per million). Ventilation and/or air purification must therefore be provided at a rate of at least 40 m³ per hour per person.
Level B: a CO2 concentration lower than 1,200 ppm or a ventilation flow of at least 25 m³ per hour per person.
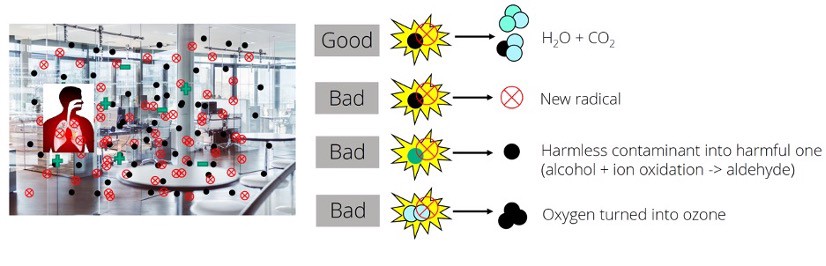
Ada yang menawarkan teknologi pembersihan udara menggunakan listrik. Teknologi ini dikenal dengan berbagai nama, seperti plasmacluster ion dan bipolar ionization (BPI)
Ada beberapa tulisan yang meragukan efektivitas alat ini. Di antaranya:
Terjemahan bebas dari Private Blog Network adalah Jaringan Blog Pribadi
PBN adalah jaringan website yang digunakan untuk menambah tautan ke website utama.
Definisi PBN
Menurut PageOnePower:
A private blog network (PBN) is a network of websites that only exist to link to a central website in order to influence that website’s authority in search [LINK]
Manfaat PBN
Fungsi PBN adalah sebagai sumber backlink untuk website utama.
Manfaat PBN adalah menaikkan otoritas website utama.
Permasalahan PBN
PBN dianggap teknik curang oleh search engine seperti Google.
Referensi
Apa itu PBN. Fungsi dan manfaatnya untuk SEO https://www.garuda.website/blog/cara-membangun-backlink-pbn/
PBNs: Everything You’ve Ever Wanted to Know But Were Afraid to Ask https://www.searchenginejournal.com/private-blog-networks/377296/