Belgia sudah mewajibkan pengukuran CO2 di tempat umum. [https://www.info-coronavirus.be/en/ventilation/]
Penelitian menganjurkan CO2 sebagai sarana mengukur resiko penularan COVID-19
Referensi
Belgia sudah mewajibkan pengukuran CO2 di tempat umum. [https://www.info-coronavirus.be/en/ventilation/]
Penelitian menganjurkan CO2 sebagai sarana mengukur resiko penularan COVID-19
Referensi
Mengecek versi CUDA di Windows 10
Pengecekan versi CUDA di Windows 10 dapat dilakukan dengan perintah “nvcc –version”
Berikut ini contoh pengecekan versi CUDA:
C:\Users\admin>nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2019 NVIDIA Corporation
Built on Sun_Jul_28_19:12:52_Pacific_Daylight_Time_2019
Cuda compilation tools, release 10.1, V10.1.243
C:\Users\admin>Tampilan di atas menunjukkan versi CUDA adalah 10.1
Apa itu Chipageddon?
Istilah ‘chipageddon’ diperkenalkan oleh orang yang biasa berkecimpung di industri mikroelektronika sebagai sebutan untuk masalah kekurangan pasokan mikrochip yang akhir-akhir ini (tahun 2020 ~ 2021) terjadi. Istilah ini adalah lakuran dari ‘microchip’ dan ‘armageddon‘
Istilah chipageddon ini memang agak berlebihan, karena armageddon kurang lebih artinya bencana besar di akhir zaman, sedangkan kekurangan pasokan microchip ini hanya menyebabkan kehidupan lebih repot, namun tidak sampai membuat kehidupan dunia berakhir.
Microchip adalah rangkaian elektronik yang digabungkan pada suatu keping kecil (‘chip’) bahan semikonduktor. Bahan semikonduktor yang paling umum dipakai adalah silikon. Microchip dikenal juga sebagai sirkuit terpadu (‘Integrated Circuit‘) atau IC.

Popular Augmentation library:
Augly (https://github.com/facebookresearch/AugLy) and Albumentations (https://github.com/albumentations-team/albumentations)
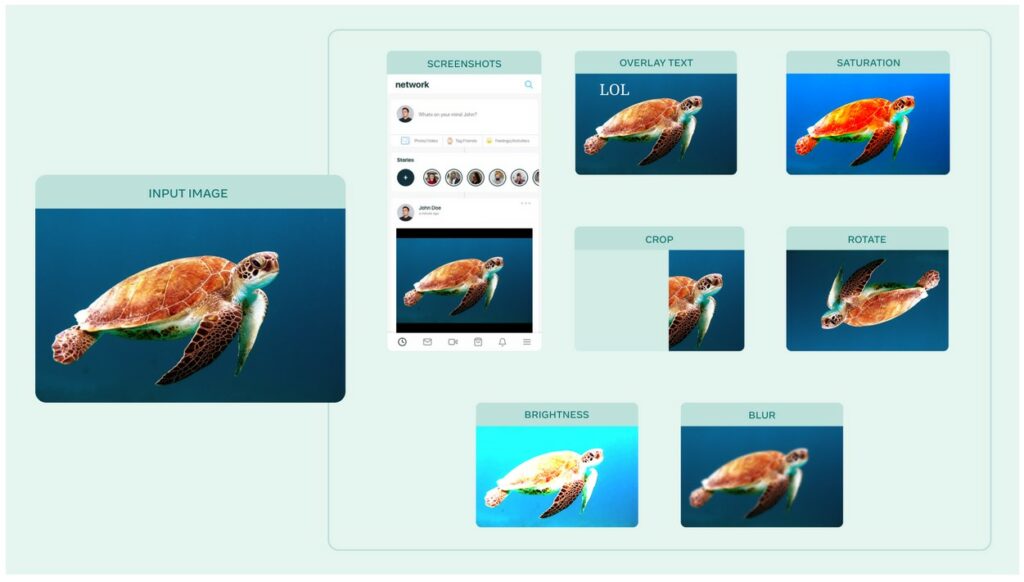
Albumentations example:

URL: https://huggingface.co/course/chapter1
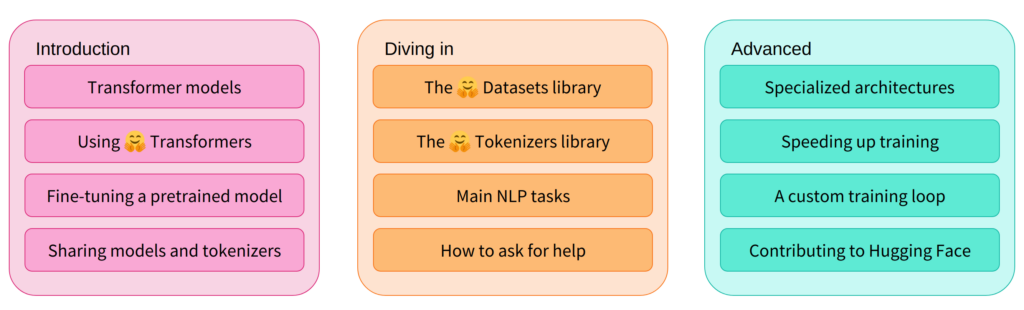
This course will teach you about natural language processing (NLP) using libraries from the Hugging Face ecosystem — 🤗 Transformers, 🤗 Datasets, 🤗 Tokenizers, and 🤗 Accelerate — as well as the Hugging Face Hub. It’s completely free and without ads.
Summary of the course:
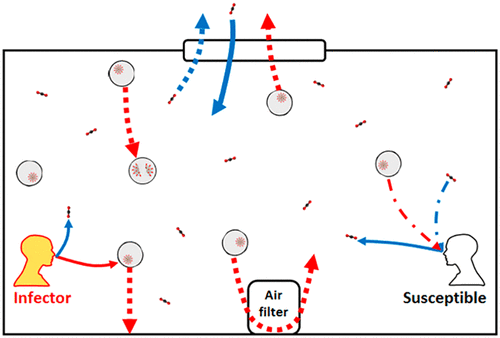
Kualitas ventilasi ruangan adalah salah satu faktor penting untuk mengurangi penularan COVID-19. Transmisi virus SARS-CoV-2 dapat melalui droplet maupun aerosol. Droplet dimensinya agak besar, sehingga terbangnya tidak terlalu jauh. Aerosol dapat terbang cukup jauh, sehingga jarak 2 meter tidak cukup aman.
Untuk mengurangi penularan maka udara di suatu ruangan harus sering diganti baru atau dibersihkan dengan filter.
Ukuran kualitas ventilasi yang sering dipakai ada 2 yaitu debit aliran udara per detik dan ACH (Air Changes per Hour).
Debit aliran udara yang dipakai adalah 10 liter per orang per detik. [1]
Angka ACH yang dipakai minimal adalah 4, kalau bisa mencapai 6 [2].
Pada artikel ini dibahas pengukuran ACH dengan sensor debu.
Virus bersifat sebagai aerosol. Aerosol disimulasikan dengan menggunakan kabut yang dibangkitkan dengan alat fog generator. Kabut ini akan meningkatkan jumlah debu dalam ruangan.
Keberadaan kabut dideteksi oleh sensor debu.
Ventilasi diaktifkan untuk mengganti udara dengan udara segar yang bersih tidak mengandung debu. Jika udara sudah berhasil diganti, maka angka debu di sensor akan turun kembali ke keadaan normal.
Peralatan yang diperlukan adalah sebagai berikut


Alternatif lain menggunakan perangkat handheld particle counter. Alat ini lebih bagus/presisi, namun juga lebih mahal. Pada pengukuran ini tidak diperlukan angka absolut jumlah debu, jadi pakai sensor murah juga sudah cukup.


Berikut ini percobaan pengkabutan di laboratorium
Berikut ini contoh grafik jumlah debu terhadap waktu.
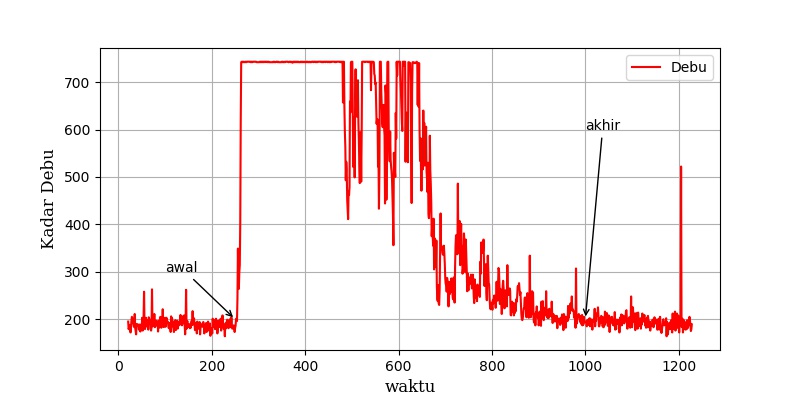
Kurva jumlah debu terhadap waktu masih banyak noise nya sehingga agak sulit melakukan analisis. Berikut ini sinyal yang sama namun dengan filter supaya sinyal frekuensi tinggi dihilangkan.
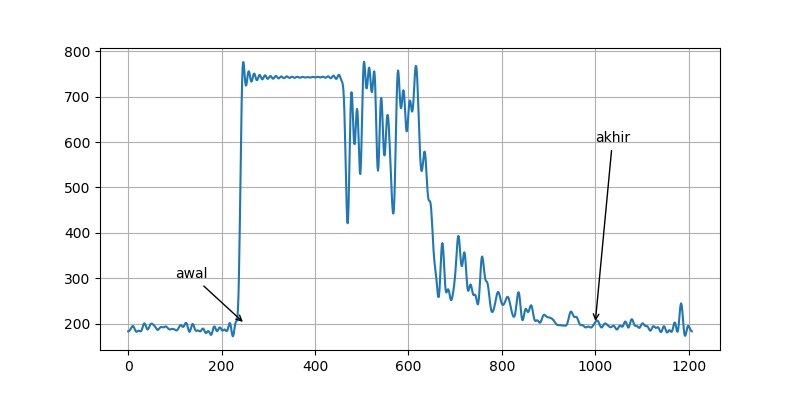
Dari kurva tersebut nampak bahwa debu mulai masuk di t=200, dan sudah hilang di sekitar t=1000. Jadi perlu waktu 800 detik untuk mengganti udara yang berkabut sampai bersih dengan udara baru.
Nilai ACH = 60 x 60 / 800 = 4,5
Jadi ruangan ini dalam 1 jam dapat melakukan pergantian udara sebanyak 4,5 kali.
A Ryzen 5 5600X processor produces the following error message:
kernel:[920812.434956] [Hardware Error]: Corrected error, no action required.
Message from syslogd@b550 at Jun 9 04:51:14 ...
kernel:[920812.441570] [Hardware Error]: CPU:1 (19:21:0) MC15_STATUS[Over|CE|-|-|-|-|-|-|-]: 0xc04100a49b07c7cb
Message from syslogd@b550 at Jun 9 04:51:14 ...
kernel:[920812.447096] [Hardware Error]: IPID: 0x0000000000000000
Message from syslogd@b550 at Jun 9 04:51:14 ...
kernel:[920812.451923] [Hardware Error]: Microprocessor 5 Unit Ext. Error Code: 7, Instruction Cache Bank B ECC or parity error.
Message from syslogd@b550 at Jun 9 04:51:14 ...
kernel:[920812.456683] [Hardware Error]: cache level: L3/GEN, tx: GEN
The computer continues working normally.
Berikut ini perintah untuk mengetahui daftar DNS server yang dipakai oleh Ubuntu 20.04, dari command line:
systemd-resolve --statusOutputnya kurang lebih seperti ini:
Global
LLMNR setting: no
MulticastDNS setting: no
DNSOverTLS setting: no
DNSSEC setting: no
DNSSEC supported: no
DNSSEC NTA: 10.in-addr.arpa
16.172.in-addr.arpa
168.192.in-addr.arpa
17.172.in-addr.arpa
18.172.in-addr.arpa
19.172.in-addr.arpa
20.172.in-addr.arpa
21.172.in-addr.arpa
22.172.in-addr.arpa
23.172.in-addr.arpa
24.172.in-addr.arpa
25.172.in-addr.arpa
26.172.in-addr.arpa
27.172.in-addr.arpa
28.172.in-addr.arpa
29.172.in-addr.arpa
30.172.in-addr.arpa
31.172.in-addr.arpa
corp
d.f.ip6.arpa
home
internal
intranet
lan
local
private
test
Link 2 (enp0s31f6)
Current Scopes: DNS
DefaultRoute setting: yes
LLMNR setting: yes
MulticastDNS setting: no
DNSOverTLS setting: no
DNSSEC setting: no
DNSSEC supported: no
Current DNS Server: 111.95.141.4
DNS Servers: 202.73.99.2
118.136.64.5
111.95.141.4
DNS Domain: domain.name
Sumber: https://askubuntu.com/questions/152593/command-line-to-list-dns-servers-used-by-my-system

AICrowd: Global Wheat Challenge 2021 solutions:
Kaggle Global Wheat Detection 2020
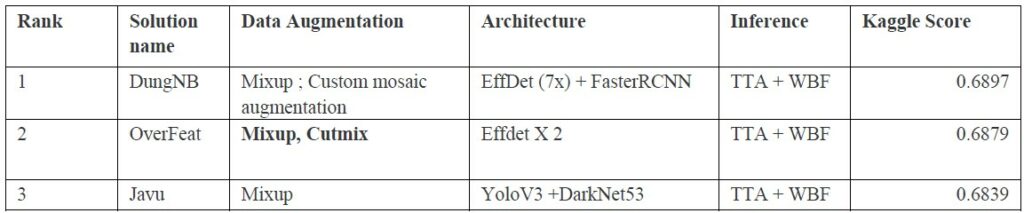
https://www.kaggle.com/c/global-wheat-detection/discussion/172418
Summary
Link: https://www.kaggle.com/c/global-wheat-detection/discussion/175961
Repository: https://github.com/liaopeiyuan/TransferDet
Code repository https://github.com/ufownl/global-wheat-detection
Papers on Out Of Domain
Yolo5 was not eligible for 2020 Wheat Head Challenge, but it can be used in 2021 Wheat Head Challenge [discussion]
Links
MySQL dilengkapi fitur load CSV, tapi fitur ini susah untuk digunakan karena seringkali format data CSV tidak sesuai dengan yang diminta, ada tanda kutip, spasi, koma yang berantakan, dll. Untuk mengatasi hal ini, Python dapat membantu dengan cara memasukkan data dengan cara membaca file CSV baris per baris ke MySQL.
Penjelasan yang lebih jelas untuk menyambung Python ke MySQL dapat dilihat di sini
Ini adalah script untuk memasukkan data CSV ke MySQL dengan menggunakan teknik looping:
import mysql.connectorimport csvmydb = mysql.connector.connect(host="host",user="root",password="pass",database="data")mycursor = mydb.cursor()with open('daftar.csv', newline='') as csvfile:reader = csv.reader(csvfile, delimiter=',')for val in reader :sql = "INSERT INTO `data`.`info` (`nama`, `data`, `nilai`) VALUES (%s,%s,%s)"mycursor.execute(sql,val)mydb.commit()mydb.close()
Data CSV yang bernama daftar.csv pada contoh memiliki format seperti ini (tanpa header):
| nama1 | data1 | nilai1 |
| nama2 | data2 | nilai2 |
| nama3 | data3 | nilai3 |